
λ計算のことは,以前の
にも少し出ていたのですが,せっかく,
でパーサを作ったので,これを利用して,本当に簡単なλ式のインタープリタを作って 遊びながら基礎を勉強するのも面白いかなと思います.ということで,ここでは型無しの λ計算(untyped lambda calculus)を動かしながら勉強します.
なお,λ計算に密接に関連しているコンビネータを動かして学ぶページも
にありますので,こちらもお楽しみください.コンビネータとλ計算,どちらが先でも
構いませんが,両方学習すると相乗効果があります.
下の ラムダ式のインタープリタを「ちょっと動かしてみる」の部分は,
試みに,

λ計算(ラムダ計算,λ-calculus)は,1930 年代に数学者のチャーチ(Alonzo Church)が 提案した計算のモデルです.もともとは数学の基礎を記述するためのシステムという 意図だったようですが,1936年にチャーチによって計算の部分だけが分離されたとのことです. λ計算は,計算を関数適用と,それと逆の関数化(抽象化)の二つのメカニズムで 組み立てます.計算はほとんど式の代入操作の繰り返しで表現されます.
まず,
などです.この変数そのものはλ式です.
はλ式です.これは,気持ち的には,何らかの値をとって,それを変数 V の値として, Expr を計算した結果を返す関数を表しています.例は次の関数適用を定義してから 示します.
はλ式です.これは気持ち的には E1 が何か関数を表していて,それを何かの
値 E2 に適用することを表しています.
上の規則から,次のようなものがラムダ式です.
変数単独でλ式というのは上ですでに述べました.λのついたものとしては,λx.x がλ式としては新しい形のλ式ですが,感覚的には,これは何か値を x にもらって,その x を返す関数です. つまり,同じものを返す関数ですね.一つ飛ばして,λx.(f x) は,x をもらって,それに何らかの関数 f を適用した結果を返す関数を表しています.一つ戻って,λx.y は何か値を受け取って それを x の値として,y を返す関数です.y の中に x は現れませんから,どこかで y に値が 設定されていれば,常にその値を返す定数関数を表しています.次の,(λx.(f x) y) は 関数 λx.(f x) を y に適用した結果を表しています.最後に,λx.λy.x は,x に値を 受け取って,さらに y に値を受け取って,そして x を返す関数ですから,二つの値を引き続いて受け取り,最初のものを返す関数を表しています.
λ式がどんなものかおよそ分かったので,今度はλ式の計算とは何かを簡単に述べます.
λ式の計算とは次の規則による変形の列のことです.
β-redex が表れたら,それを,Expr1 の中の変数 V を Expr2 に置き換えたものに 置き換えてよいというのがβ変換の規則です.
λV.Expr を λV2.Expr2 に置き換えてよい
という計算規則です.例えば,λx.(f x) を,λy.(f y) に置き換えるのはα変換です.
今回作るλ式のインタープリタではα変換を明示的に行う機能は提供しません. β変換を行うのに変数名がぶつかって不都合が起きるとき,システムが自動的に α変換を行うようになっています.一応,α変換の概念だけは押さえておいてください.
計算の例
(((λx.λy.y) x) y) -> (λy.y y) -> y
((λx.λy.y) x) を計算して(λy.y y) を得て,さらにそれを計算
(λg.λf.λx.(f ((g f) x)) λf.λx.(f (f x)))
左の g に右のλf.λx.(f (f x))を代入
-> λf.λx.(f ((λf.λx.(f (f x)) f) x))
内部の(λf.λx.(f (f x)) f)を計算
-> λf.λx.(f (λx.(f (f x)) x))
内部の(λx.(f (f x)) x)を計算
-> λf.λx.(f (f (f x)))
この2番目のは何をやっているか分かりますでしょうか.二番目の最初の式の後ろの項は,λf.λx. の後に,
x に f を2回適用した形になっています.それに最初のλ式を適用したら,最終的な結果として x に
f を3回適用した形になっています.右側に f と x をとって,x に f をn 回適用する
λ式があるとき,左側のλ式はそれを f の n+1 回の適用に書き換えると言う作用を持っています.
なんとなく計算が出来るような雰囲気がでてきたでしょう.このページではこういうことを
λ式のインタープリタを使って確かめながら学びます.

ちょっとだけ動かしてみましょう.
まず,対話的に実行できる Ruby のインタープリタを入手します.Ruby のバージョンは 2.3 以降なら動くと思います(今(2019年2月19日現在)は,Version 2.6 位ですかね)
次に,「簡単な演算子順位法によるパーサー in Ruby」の パーサーの掲載リスト から,その掲載リストをコピーして,ファイルに保存し,Ruby に読み込みます.
最後に,このページの
λ式のインタープリタの掲載リスト
をやはり,コピーしてファイルに保存し,先ほどパーサーを読み込ませた Ruby に
続いて読み込ませます.
以上で準備は整いましたので,Ruby のインタープリタで ltop という関数を動かしてください. ltop の最初の l(小文字のエル) は lambda 式の l です.前に作った SKI インタープリタのとき top を 使ってしまったので,top が使えなくなってしまったので,先頭に l を付けました.
動かす前に,ちょっと,記述方法の注意が2つあります.
こちらはλ計算一般の記法です.
まず,ruby のインタープリタ(irb など)を起動します.
c:\0-ruby\sop>irb
続いて,演算子順位法のパーサを load します.私は,
ファイル名 sop.rb としていますから,load "sop.rb" です.ここらあたりは,
ruby が分かる人なら,次のλ式のインタープリタの方に,require かなにかを
書いておいて省略することができます.
irb(main):003:0> load "sop.rb"
=> true
次にλ式のインタープリタを load します.私は,ファイル名を
"lambda.rb" としています.
irb(main):004:0> load "lambda.rb"
=> true
準備が整いましたので,関数 ltop を呼んで下さい.
ltop はインタープリタ用のコマンドの解釈や入力されたλ式の変換を行って結果を
表示します.どんなコマンドが使えるかなどのヘルプは組み込んでいませんので,
コマンドはこのページの説明を参照してください.
irb(main):005:0> ltop
まず,:s コマンドを入れます.これは,いま,このツールにどのような名前が
定義されているかを列挙します.「名前」というのは何かλ式に付けられた「名前」で
このツールではその名前で対応するλ式を表すことができるようになっています.
最初は,システム組み込みの名前,S, K, I だけが組み込まれています.
lb> :s
Identifier(s):
S := x.y.z.(x z (y z))
K := x.y.x
I := x.x
ユーザも名前を作ることができます.試しに,aaa という名前で
前節の最後で,β変換の最初の例を指すようにしてみましょう.
それには,次のように 名前 := λ式 のように入れてください.
λ式の部分は前節の説明のものから,λの部分を取り去ったものを
注意深く入れてください.
lb> aaa:=(x.y.y) x y
定義されたかどうか見てみましょう.
lb> :s
Identifier(s):
S := x.y.z.(x z (y z))
K := x.y.x
I := x.x
aaa := x.y.y x y
確かに aaa が加わっています.右のλ式は入力のものより少し括弧が少ない
ように見えますが,このツールでは表示の時に演算子の結合度で,括弧が
不要な部分は省略して表示するようになっていますので,最初は慣れないかも
しれませんが,頭の中で適当に括弧を補ってみてください.
このツールではλ式を入力すると,即,実行(変換列を作ること)を
始めます.それは直接,λ式を入れなくても,名前を入れると,
その定義が展開され,λ式が入力されたことになります.
では,前節の変換が正しかったかどうかやってみましょう.
lb> aaa
Input = x.y.y x y
[x.y.y] # [x] -> y.y
0 -> y.y y
[y.y] # [y] -> y
1 -> y
Result = y
はい,確かに前節の通り,y になりました.
途中に色々な式を出力していますが,それらについて説明しておきます.
まず,Input=... は,入力した式の中の名前を展開したら ... になると
言う意味です.
[V.Expr1] # [Expr2] -> Expr3 は,β変換 (V.Expr1 Exp2) -> Expr3 が
行われたことを表します.
左に数字がついた式は,それ以前に書かれているβ変換の結果,その式が
得られたことを表します.
このツールはこのような変換の詳細情報を出力しながら動作します.この出力は
:verbose コマンドで出ないようにできますが,まあ,教育用のツールなので,
しっかり変換の後を追いながら勉強してください.
λ抽象化では変数名を変えても,その式の中の変数も同様に変えれば
意味は変わりませんでした(α変換).
試しに,上のx, y を,u, v に変えてやってみましょう.
lb> u.v.v x y
Input = u.v.v x y
[u.v.v] # [x] -> v.v
0 -> v.v y
[v.v] # [y] -> y
1 -> y
Result = y
はい,答えは一緒でした.
次は前節の2つ目の例です.自然数の 2 相当のものに,1 相当のものを
足すというやつです.式が長いので,名前を次のように定義しておきましょう,
lb> two := f.x.(f (f x))
lb> add1 := g.f.x.(f ((g f) x))
ちゃんと定義できたかどうか確かめてみます.
lb> :s
Identifier(s):
S := x.y.z.(x z (y z))
K := x.y.x
I := x.x
aaa := x.y.y x y
two := f.x.(f (f x))
add1 := g.f.x.(f (g f x))
大丈夫でした.
では,前節の例を動かしてみましょう.
lb> add1 two
Input = g.f.x.(f (g f x)) f.x.(f (f x))
[g.f.x.(f (g f x))] # [f.x.(f (f x))] -> f.x.(f (f.x.(f (f x)) f x))
0 -> f.x.(f (f.x.(f (f x)) f x))
[f.x.(f (f x))] # [f] -> x.(f (f x))
1 -> f.x.(f (x.(f (f x)) x))
[x.(f (f x))] # [x] -> f (f x)
2 -> f.x.(f (f (f x)))
Result = f.x.(f (f (f x)))
確かに f が3つ,x に適用される形になりました.
add1 を2回適用してみましょう.
lb> add1 (add1 two)
Input = g.f.x.(f (g f x)) (g.f.x.(f (g f x)) f.x.(f (f x)))
[g.f.x.(f (g f x))] # [g.f.x.(f (g f x)) f.x.(f (f x))] -> f.x.(f (g.f.x.(f (g f x)) f.x.(f (f x)) f x))
0 -> f.x.(f (g.f.x.(f (g f x)) f.x.(f (f x)) f x))
[g.f.x.(f (g f x))] # [f.x.(f (f x))] -> f.x.(f (f.x.(f (f x)) f x))
1 -> f.x.(f (f.x.(f (f.x.(f (f x)) f x)) f x))
[f.x.(f (f.x.(f (f x)) f x))] # [f] -> x.(f (f.x.(f (f x)) f x))
2 -> f.x.(f (x.(f (f.x.(f (f x)) f x)) x))
[x.(f (f.x.(f (f x)) f x))] # [x] -> f (f.x.(f (f x)) f x)
3 -> f.x.(f (f (f.x.(f (f x)) f x)))
[f.x.(f (f x))] # [f] -> x.(f (f x))
4 -> f.x.(f (f (x.(f (f x)) x)))
[x.(f (f x))] # [x] -> f (f x)
5 -> f.x.(f (f (f (f x))))
Result = f.x.(f (f (f (f x))))
f が4つになりました.
掛け算は次のようにして作ることができます.
lb> mult := x.y.f.(x (y f))
定義を確認してみましょう.
lb> :s
Identifier(s):
S := x.y.z.(x z (y z))
K := x.y.x
I := x.x
aaa := x.y.y x y
two := f.x.(f (f x))
add1 := g.f.x.(f (g f x))
mult := x.y.f.(x (y f))
ではやってみます.
lb> mult (add1 two) two
Input = x.y.f.(x (y f)) (g.f.x.(f (g f x)) f.x.(f (f x))) f.x.(f (f x))
[x.y.f.(x (y f))] # [g.f.x.(f (g f x)) f.x.(f (f x))] -> y.f.(g.f.x.(f (g f x)) f.x.(f (f x)) (y f))
0 -> y.f.(g.f.x.(f (g f x)) f.x.(f (f x)) (y f)) f.x.(f (f x))
[y.f.(g.f.x.(f (g f x)) f.x.(f (f x)) (y f))] # [f.x.(f (f x))] -> f.(g.f.x.(f (g f x)) f.x.(f (f x)) (f.x.(f (f x)) f))
1 -> f.(g.f.x.(f (g f x)) f.x.(f (f x)) (f.x.(f (f x)) f))
[g.f.x.(f (g f x))] # [f.x.(f (f x))] -> f.x.(f (f.x.(f (f x)) f x))
[f.x.(f (f x))] # [f] -> x.(f (f x))
2 -> f.(f.x.(f (f.x.(f (f x)) f x)) x.(f (f x)))
[f.x.(f (f.x.(f (f x)) f x))] # [x.(f (f x))] -> x.(x.(f (f x)) (f.x.(f (f x)) x.(f (f x)) x))
3 -> f.x.(x.(f (f x)) (f.x.(f (f x)) x.(f (f x)) x))
[x.(f (f x))] # [f.x.(f (f x)) x.(f (f x)) x] -> f (f (f.x.(f (f x)) x.(f (f x)) x))
4 -> f.x.(f (f (f.x.(f (f x)) x.(f (f x)) x)))
[f.x.(f (f x))] # [x.(f (f x))] -> x.(x.(f (f x)) (x.(f (f x)) x))
5 -> f.x.(f (f (x.(x.(f (f x)) (x.(f (f x)) x)) x)))
[x.(x.(f (f x)) (x.(f (f x)) x))] # [x] -> x.(f (f x)) (x.(f (f x)) x)
6 -> f.x.(f (f (x.(f (f x)) (x.(f (f x)) x))))
[x.(f (f x))] # [x.(f (f x)) x] -> f (f (x.(f (f x)) x))
7 -> f.x.(f (f (f (f (x.(f (f x)) x)))))
[x.(f (f x))] # [x] -> f (f x)
8 -> f.x.(f (f (f (f (f (f x))))))
Result = f.x.(f (f (f (f (f (f x))))))
もう見る気が無くなりそうな出力ですが,最後の行の結果だけを
確認してみると f が 2 × 3 = 6 になっていることが分かります.
では,いったんツールを抜けましょう.それには,コマンド :q を
入れます.
lb> :q
=> nil
Ruby のインタープリタに抜けましたので,quit とか exit で抜けてください.
このページで初めてλ計算を勉強する人は,新しいことが沢山で疲れたと思います. この「ちょっと動かしてみる」では,もう一セッションの説明があります.それは, 本ツールのいくつかの便利な機能についてです.しかし,上で説明したことだけでも, 実は,λ式でいろいろな計算ができることを示すことができます.この先,すぐ続けて 読む気力が起きないという方は,しばらく,例えば, Wikipedia のλ計算のページでも 見ながら色々な式を入れて遊んでみてください.中には,不動点コンビネータ Y の ように止まらないλ式もありますが,初期の設定では,変換回数の上限を 40 としてありますので,沢山の出力を出した後に止まります.ただし,λ式の中には 急速に大きくなるものもあり,そういうものは 40 回でも到達できないかもしれません. そのようなときは,Ctrl-C などで止めてください.
では気力がでたら,次のセッションの説明を読んで下さい.今回は,複雑なλ式の 構造を表示する機能と,変換をワンステップずつ実行する機能を説明します.
セッション1からの続きです.ltop を抜けた方は,もういちど
ltop を起動してください.たぶん,まだ,先ほどの名前の定義は残っています.
Ruby のインタープリタまで抜けた方は,もういちどセッション1で行った名前の
定義をやり直してください.
irb(main):009:0> ltop
まず,前回の定義が残っているかどうか調べてみましょう.
lb> :s
Identifier(s):
S := x.y.z.(x z (y z))
K := x.y.x
I := x.x
aaa := x.y.y x y
two := f.x.(f (f x))
add1 := g.f.x.(f (g f x))
mult := x.y.f.(x (y f))
はい,残っていました.残ってないときは,コピペで再度
定義すれば簡単に定義できます.ちなみに Windows 10 のコマンドプロンプトでは,
Shift-Ins キーで,ペーストできます.コマンドプロンプトでのコピーは
範囲を選択してエンターですね.
では,aaa の構造をみるために :p コマンドを次のように使います.
lb> :p aaa
Input = x.y.y x y
Tree = ((x.y.y
|#
|x%)
y%)
何やら変な表示がでました.Input は入力した式そのものです.
ここでは,名前 aaa を定義に従って展開したら,x.y.y x y になるということを
表しています.Tree の中の下の方の x%, y% の % は今は無視してください.
後で説明します.今は,それが無いと思ってください.
この表示はλ式の中の式間の適用関係を表しています.# が縦に続くところは
β-redex の関係で,| が縦に続くのはそれ以外の関数適用を表しています.
この表示では # は続くと言っても,一つだけで続く感じは出てないかも
しれませんが,式の間が離れていれば続きます.何となくネットハックを思い
起こさせる表示ですね.
では上の表示を読んでみましょう.まず,中の # の方から見ます.これは # の上の
λ式 x.y.y を下の x に適用する形になっているということを表します.aaa を
展開した式は括弧を付ければ,((x.y.y x) y) です.この内側の括弧の中
(x.y.y x)
は,前がλx.λy.y で後ろが x なので,β-redex になっています.上の表示の # は
それを表しています.
次に | ですが,元の式は (x.y.y x) をさらに y に適用する形になっています.
このとき適用する関数側は,字面通りならβ-redex にはなっていません.
そこで,この表示ではβ-redex となる表示と区別して,| で適用関係を
表しています.
では,今度は add1 を表示してみましょう.これも見た目,良く分からない式でした.
lb> :p add1
Input = g.f.x.(f (g f x))
Tree = g.f.x.(f
|
((g
||
|f)
x))
関数適用が3か所に現れています.しかし,β-redex はありません.
したがって,これはこのままでは変換できない式です.
まあ,すごく分かりやすい表示になったかというとそうでもありませんが,
関数適用のかかり方と,β-redex の所在だけは分かるようになったと思います.
次にこれを two に適用したλ式の構造をみてみます.
lb> :p (add1 two)
Input = g.f.x.(f (g f x)) f.x.(f (f x))
Tree = (g.f.x.(f
# |
# ((g
# ||
# |f)
# x))
f.x.(f
|
(f
|
x)))
β-redex は1つです.つまり,add1 を two に適用する部分ですね.
次にもう一つ,式の構造を :p で表示してみます.
S, K, I は最初から定義されているλ式の名前です.これは :s コマンドで
確かめておいてください.次の式はずいぶん複雑な式です.not := ... と
なっているのは,これが論理演算の not だからです(ここではそれほど
意味はありませんが).
lb> not := (S (S I (K (K I))) (K K))
表示してみます.
lb> :p not
Input = x.y.z.(x z (y z)) (x.y.z.(x z (y z)) x.x (x.y.x (x.y.x x.x))) (x.y.x x.y.x)
Tree = ((x.y.z.((x
|# ||
|# |z)
|# (y
|# |
|# z))
|((x.y.z.((x
| |# ||
| |# |z)
| |# (y
| |# |
| |# z))
| |x.x)
| (x.y.x
| #
| (x.y.x
| #
| x.x))))
(x.y.x
#
x.y.x))
β-redex が沢山あります.実は,これが言いたかっただけです.
一般にλ式の中にはβ-redex が複数あることがあります.その中のどれを先に
変換するかでλ式の変換が止まるかどうかが決まることがあります.そういうことを
λ計算では勉強しますので,β-redex がどこにあるか確かめることが重要になります.
ついでに not を変換してみましょう.
lb> not
Input = x.y.z.(x z (y z)) (x.y.z.(x z (y z)) x.x (x.y.x (x.y.x x.x))) (x.y.x x.y.x)
[x.y.z.(x z (y z))] # [x.y.z.(x z (y z)) x.x (x.y.x (x.y.x x.x))] -> y.z.(x.y.z.(x z (y z)) x.x (x.y.x (x.y.x x.x)) z (y z))
[x.y.x] # [x.y.x] -> y.x.y.x
0 -> y.z.(x.y.z.(x z (y z)) x.x (x.y.x (x.y.x x.x)) z (y z)) y.x.y.x
[y.z.(x.y.z.(x z (y z)) x.x (x.y.x (x.y.x x.x)) z (y z))] # [y.x.y.x] -> z.(x.y.z.(x z (y z)) x.x (x.y.x (x.y.x x.x)) z (y.x.y.x z))
1 -> z.(x.y.z.(x z (y z)) x.x (x.y.x (x.y.x x.x)) z (y.x.y.x z))
[x.y.z.(x z (y z))] # [x.x] -> y.z.(x.x z (y z))
[x.y.x] # [x.y.x x.x] -> y.(x.y.x x.x)
[y.x.y.x] # [z] -> x.y.x
2 -> z.(y.z.(x.x z (y z)) y.(x.y.x x.x) z x.y.x)
[y.z.(x.x z (y z))] # [y.(x.y.x x.x)] -> z.(x.x z (y.(x.y.x x.x) z))
3 -> z.(z.(x.x z (y.(x.y.x x.x) z)) z x.y.x)
[z.(x.x z (y.(x.y.x x.x) z))] # [z] -> x.x z (y.(x.y.x x.x) z)
4 -> z.(x.x z (y.(x.y.x x.x) z) x.y.x)
[x.x] # [z] -> z
[y.(x.y.x x.x)] # [z] -> x.y.x x.x
5 -> z.(z (x.y.x x.x) x.y.x)
[x.y.x] # [x.x] -> y.x.x
6 -> z.(z y.x.x x.y.x)
Result = z.(z y.x.x x.y.x)
not をλ式で書くとこのようになり,上の S, K, I で書いたものより
ずいぶん簡単になります.上の式は,別のページでも紹介していますが,
ここで定義した S, K, I で任意のλ式がシミュレートできることを示す
ためのものです.
まあ,ついでなので,λ式の true を表す,x.y.x に適用してみます.
lb> not x.y.x
Input = x.y.z.(x z (y z)) (x.y.z.(x z (y z)) x.x (x.y.x (x.y.x x.x))) (x.y.x x.y.x) x.y.x
[x.y.z.(x z (y z))] # [x.y.z.(x z (y z)) x.x (x.y.x (x.y.x x.x))] -> y.z.(x.y.z.(x z (y z)) x.x (x.y.x (x.y.x x.x)) z (y z))
[x.y.x] # [x.y.x] -> y.x.y.x
0 -> y.z.(x.y.z.(x z (y z)) x.x (x.y.x (x.y.x x.x)) z (y z)) y.x.y.x x.y.x
[y.z.(x.y.z.(x z (y z)) x.x (x.y.x (x.y.x x.x)) z (y z))] # [y.x.y.x] -> z.(x.y.z.(x z (y z)) x.x (x.y.x (x.y.x x.x)) z (y.x.y.x z))
1 -> z.(x.y.z.(x z (y z)) x.x (x.y.x (x.y.x x.x)) z (y.x.y.x z)) x.y.x
[z.(x.y.z.(x z (y z)) x.x (x.y.x (x.y.x x.x)) z (y.x.y.x z))] # [x.y.x] -> x.y.z.(x z (y z)) x.x (x.y.x (x.y.x x.x)) x.y.x (y.x.y.x x.y.x)
2 -> x.y.z.(x z (y z)) x.x (x.y.x (x.y.x x.x)) x.y.x (y.x.y.x x.y.x)
[x.y.z.(x z (y z))] # [x.x] -> y.z.(x.x z (y z))
[x.y.x] # [x.y.x x.x] -> y.(x.y.x x.x)
[y.x.y.x] # [x.y.x] -> x.y.x
3 -> y.z.(x.x z (y z)) y.(x.y.x x.x) x.y.x x.y.x
[y.z.(x.x z (y z))] # [y.(x.y.x x.x)] -> z.(x.x z (y.(x.y.x x.x) z))
4 -> z.(x.x z (y.(x.y.x x.x) z)) x.y.x x.y.x
[z.(x.x z (y.(x.y.x x.x) z))] # [x.y.x] -> x.x x.y.x (y.(x.y.x x.x) x.y.x)
5 -> x.x x.y.x (y.(x.y.x x.x) x.y.x) x.y.x
[x.x] # [x.y.x] -> x.y.x
[y.(x.y.x x.x)] # [x.y.x] -> x.y.x x.x
6 -> x.y.x (x.y.x x.x) x.y.x
[x.y.x] # [x.y.x x.x] -> y.(x.y.x x.x)
7 -> y.(x.y.x x.x) x.y.x
[y.(x.y.x x.x)] # [x.y.x] -> x.y.x x.x
8 -> x.y.x x.x
[x.y.x] # [x.x] -> y.x.x
9 -> y.x.x
Result = y.x.x
これは心の中でα変換すると,x.y.y になります.そして,これは
λ計算で false を表す式でもあります.
もう一つの機能のワンステップ実行を説明します.
今まではλ式を入力すると突然膨大な出力を表示し始めて,なにやら別のλ式になり,
ちょっと理解が追いつかないことがあったと思います.ワンステップ実行では,これを
1回の変換ごとに留めて表示します.ワンステップ実行モードに入るには :o コマンドを
入力します.これは入力するごとに,ON/OFF が入れ替わります.最初はOFF に
なっています.
はい,ON にします.
lb> :o
interactive mode = true
add1 two を変換してみましょう.
lb> add1 two
Input = g.f.x.(f (g f x)) f.x.(f (f x))
[g.f.x.(f (g f x))] # [f.x.(f (f x))] -> f.x.(f (f.x.(f (f x)) f x))
0 -> f.x.(f (f.x.(f (f x)) f x))
Enter, c, q ?:
一回の変換を行って止まりました.ここで,エンターを押せば
次の一回の変換が起こります.c エンターを押せば,次は止まらないで最後まで
変換されます.やめたければ,q エンターを入力します.
[f.x.(f (f x))] # [f] -> x.(f (f x))
1 -> f.x.(f (x.(f (f x)) x))
Enter, c, q ?:
[x.(f (f x))] # [x] -> f (f x)
2 -> f.x.(f (f (f x)))
Enter, c, q ?:
Result = f.x.(f (f (f x)))
lb>
まあ,最後まで実行して,スクロールしながらログを追って行けば,
同じと言えば同じなのですが,実際に実行しているときにそれを見ながら
理解するのとは若干気分が違います.
以上で,「ちょっと動かしてみる」は終わりです.あとは,このツールの個別の機能の説明と λ計算の基礎のお話になります.
一応,一通り,簡易λ式インタープリタの機能の説明をしておきます.
利用のための環境ですが,Ruby の バージョン 2.3 以降と,対話型インタープリタが あれば利用可能と思います.私は Windows 10 で, irb を使っていますが, Linux でも irb は動いているみたいなので本インタープリタを利用可能でしょう. Mac についてはあまり良く知りませんが,irb はあるようですね.android の ruboto などの 環境では,それぞれの ruby の関数は実行可能なのですが,read-eval loop が書けないので 本ページのプログラムをそのまま利用することはできません.
続いて,起動と終了ですが,Ruby の対話型インタープリタ(irb など)に,
を読み込んだ後,以下に掲載した 簡易λ式インタープリタの掲載リスト を読み込んで,関数 ltop を呼び出してください.そうすれば,簡易λ式インタープリタに 入ります.終了するためにはコマンド :q を入れて改行を入れてください.Ruby の インタープリタに戻ります.
簡易λ式インタープリタで利用可能なコマンドは次の通りです.
例:
名前 true を定義
lb> true := x.y.x
現在定義されている名前の表示
lb> :s
Identifier(s):
S := x.y.z.(x z (y z))
K := x.y.x
I := x.x
true := x.y.x
名前を全部消す
lb> :clear
Identifiers all cleared
消えたことを確認
lb> :s
Identifier(s):
確かに消えている
名前の定義をファイルから読み込む.
"sys.def" は後でリストを掲載してある.
lb> :load "sys.def"
File "sys.def" loaded
読み込まれたことを確認
lb> :s
Identifier(s):
S := x.y.z.(x z (y z))
K := x.y.x
I := x.x
B := x.y.z.(x (y z))
C := x.y.z.(x z y)
true := x.y.x
false := x.y.y
Y0 := x.(f (x x))
Y := f.(x.(f (x x)) x.(f (x x)))
is_zero := n.(n u.x.y.y x.y.x)
suc := n.f.x.(f (n f x))
pred := n.f.x.(n g.h.(h (g f)) u.x u.u)
plus := m.n.f.x.(m f (n f x))
pair := x.y.f.(f x y)
1st := p.(p x.y.x)
2nd := p.(p x.y.y)
nil := x.x.y.x
null := p.(p x.y.x.y.y)
確かに読み込まれている
lb>
例
λ式 f.g.x.(f (g x)) で関数 g は引数 x に適用され,関数 f は
その結果に適用されています.(もちろんλ計算では関数とデータの違いは
ありませんから,あくまで,記述場所から我々の思いを込めて「関数」,「データ」,
「引数」などと呼んでいるだけですが)
:p はその適用関係を「|」で示しています.
lb> :p f.g.x.(f (g x))
Input = f.g.x.(f (g x))
Tree = f.g.x.(f
|
(g
|
x))
次は最初に適用する関数を f でなく,u.(f u) というλ抽象化された
式にしてみます.
lb> :p f.g.x.(u.(f u) (g x))
Input = f.g.x.(u.(f u) (g x))
Tree = f.g.x.(u.(f
# |
# u)
(g
|
x))
β-redex の部分が「|」でなく「#」で表示されるようになりました.
次は先頭の,f. の部分を取り去ると,f はこのλ式のパラメータとして
与えられていません.そのような変数を自由変数と言います.C言語でいうと
グルーバル変数のようなものです(正確にはもうちょっと広い概念ですが).
lb> :p g.x.(f (g x))
Input = g.x.(f (g x))
Tree = g.x.(f%
|
(g
|
x))
この場合は f の後ろに % が付きました.このように :p では
パラメータとして受け取っていない変数には % が付くようになっています.
この機能を利用して,どこに自由変数があるのかを :p で調べることができます.
lb>
1 -> f.x.(f (x.(f (f x)) x)) Enter, c, q ?:のように聞いてきます.単にエンターを押せば,次の変換を行い,文字 c を入れて エンターを押せば最後の評価まで進み,文字 q を入れてエンターを押せば変換をやめます.
η変換とは λx.(E x) で E に x が自由変数として現れなければ,E に変換すると いう変換です.詳しくは次節のλ計算の基礎を参照してください.η変換は最初は OFF になっています.
変換戦略にはいろいろなバリエーションがありますので,興味のある人は 調べて,組み込んでみるのも勉強になります.
このモードの初期値は,:all で :strat が入力されるごとに入れ替わります.
式は入力されると,まず名前の定義を調べ,それが展開されます.また,式の中には チャーチ数の短縮された書き方 ($3) など特殊な書き方ができるものが用意されています. これについては次の「式の中で使える特殊な表現」に書きます.
展開された式は,β変換(η変換が許可されている場合はそれも)が繰り返され, 変化しないようになったら停止して,それが計算の結果と見なされます.変換の 過程は,端末に逐次に表示されます.表示の単位は,実装依存です.:innermost の 場合は,式の内側かつ左側からβ-redex を調べていき,見つかったものを変換します. 内側から外側まで1度調べて見つかったものを全部変換したら一回の変換としています. そうして変換した結果,また,β-redex ができる可能性がありますので,何ステップも 変換が続くことがあるわけです.変換戦略が outermost のときは,外側かつ左側 から調べ,β-redex が見つかったら,そこだけ変換して一回のステップを終わります. η変換も同様に変換戦略に従って,変換されます.
インタープリタに入力した式のうち,次の式は特殊な意味を持ちます.
自然数 n ≥ 0 のチャーチ数は次のようなλ式です.
f.x.(f (f ...(f x)...))
ここで,f の個数は n 個です.例えば, ($0) = f.x.x, ($3) = f.x.(f (f (f x))) です.
:p コマンドでも構造を確認しておきましょう.
lb> :p ($3)
Input = f.x.(f (f (f x)))
Tree = f.x.(f
|
(f
|
(f
|
x)))
この記法を使えば,「ちょっと動かしてみる」で書いた two は,($2) と書けます.
u.(f u u)//(f=x.y.x)
は,
u.(x.y.x u u)
のように変換されます.Exp1 の中の束縛された変数は変更されません.
λ式の書き方についていくつか注意事項があります.
実はこの書き方が,多くのλ式の書籍や Wikipedia などと違うのです.これは 今回使ったパーサーの特性から仕方なくこの規則にしました.一般の書籍では λu.f u は,λu.(f u) と解釈され,これを z に適用するときは, (λu.f u) z になると思います.
なぜこのようなことになったかというと,空白で関数適用を表し,それらを
演算子順位法で解析するためには,トッドを空白以上の優先度にする必要が
ある(空白の方がドットより結合度が強いかあるいは同じ).このように
すれば,u.a b が u.(a b) のように解釈されるのだが,u.a v.b を解析しようと
したとき,演算子文法では,u.(a b).b の括り方が発生してしまう.これを検出し,きちんと
我々の希望通り括りなおすのは,今回のように,ざっと短いプログラムで
作ってしまうという趣旨とはうまく折り合わないと考えたことが今回の仕様採択の
理由である.2019.02.18
ここではλ計算のインタープリタを使って,λ計算のごく初歩部分だけを勉強します. 理論的な部分は他の成書に譲るとして,それらの成書を読むとき,読者が心の中に λ計算の計算過程のイメージを抱けるようになることを目的とします.そのために なにか計算らしいことがλ計算のメカニズムで実現できるということを体験するまでを この節の目的とします.
λ式の定義など,概略の章などとかなり重複しますが,この節をまとまって 読めるために,あえて重複的な記述も行います.
まず,λ式の定義から始めます.
まず可算無限個の変数が用意されているとします(「可算無限個」という用語を知らなければ,
無限個と思って結構です).このページでは特に断らない限り,アルファベットと数字からなる任意の文字列が変数とします.この準備のもとに
などです.この変数そのものはλ式です.
はλ式です.これは気持ち的には E1 が何か関数を表していて,それを何かの 値 E2 に適用することを表しています.
はλ式です.これは,気持ち的には,何らかの値をとって,それを変数 V の値として, Expr を計算した結果を返す関数を表しています. 本などでは,λ抽象化は前にλという文字を書くのですが,ここの説明では,今回作成したλ式のインタープリタの記法と合わせて, これを
と書くことにします.
上の規則から,次のようなものがラムダ式です.
x, y, f.g.h.x.(f (g (h x))), x.y.f.((f x) (u.(u u) y))
最初は中々λ式の構造を見て取ることができないと思います.例えば,最後から二つ目のλ式
x.y.f.((f x) (u.(u u) y))
は,どこに関数適用があり,どこに抽象化があるのか見て取るのは難しいのではないでしょうか. ちょっと,今回のインタープリタの :p コマンドで構造を見て取ることができます. でも,まず,ちょっと簡単な f.g.h.x.(f (g (h x))) を見てみましょう.
lb> :p f.g.h.x.(f (g (h x)))
Input = f.g.h.x.(f (g (h x)))
Tree = f.g.h.x.(f
|
(g
|
(h
|
x)))
このように表示されました.この図(正確には ASCII ART ですが)で「|」で上下に結ばれているのが 関数適用の箇所です.下から見ると,x に h に適用したものに g を適用して,それに f を 適用しています.そして,そこで使われた変数すべてが,その外側にλ抽象化で並べられています.
次は,最後から二番目の式の表示をしてみましょう.
lb> :p x.y.f.((f x) (u.(u u) y))
Input = x.y.f.(f x (u.(u u) y))
Tree = x.y.f.((f
||
|x)
(u.(u
# |
# u)
y))
この図では「|」のほかに「#」も使われていますが,どちらも関数適用です( 「#」については次で説明します). つまり f を x に,(f x) を (u.(u u) y) へ,u を u へ, u.(u u) を y への4か所に 関数適用があるということです.:p はこのように関数適用がどこにあるかを認識するために 使うことができます. 次に,λ式の中に現れる変数の現れ方に関する用語を定義しておきます.
束縛変数と自由変数が直観的に何を表しているのかを述べておきます.束縛変数は プログラミング言語のパラメータだと思うことができます.何か値を受け取って, 以後,それが表れたところでは,その受け取った値を表す.それに対して,自由変数は パラメータで束縛される外側にある変数です.C言語では大域変数が自由変数の例に なります.皆さんにはなじみはあまりないかもしれませんが,プログラミング言語 PASCAL では,変数のスコープの階層がありました.そのようなプログラミング言語では 自由変数は外のスコープにある変数です.
この自由変数がどこに現れるかも,先ほどのコマンド :p で知ることができます. 上で述べた自由変数の登場する式 x.y.(f (x y)) を表示してみましょう.
lb> :p x.y.(f (x y))
Input = x.y.(f (x y))
Tree = x.y.(f%
|
(x
|
y))
自由変数 f には後ろに % がついています.このような簡単な式ではすぐ自由変数の所在が
分かりましたが,複雑な式ではなかなか見つからないこともあります.λ式の見方に
なれるために,:p を活用してください.
λ式が定義できたので,今度はλ式の計算とは何かを述べます.
まず,λ式に次の二つの変換規則,α変換とβ変換を導入します.
(このツールの記法では,
という変換規則です.例えば,λx.(f x) を,λy.(f y) に置き換えるのはα変換です.
いくつか例を挙げてみます.
lb> :p (x.(f x) u.(u u))
Input = x.(f x) u.(u u)
Tree = (x.(f%
# |
# x)
u.(u
|
u))
「#」でつながれているところがありますから,確かにβ-redex があり,
前のλ式には自由変数 f がありますが,後ろのλ式にはありませんね.
これは,β変換ができて,前の式の x に後ろの式 u.(u u) を入れればよいので
f u.(u u) になります.これもやってみましょう.
lb> (x.(f x) u.(u u))
Input = x.(f x) u.(u u)
[x.(f x)] # [u.(u u)] -> f u.(u u)
0 -> f u.(u u)
Result = f u.(u u)
確かに,f u.(u u) になりました.
lb> x.y.(u.(u u) y)
Input = x.y.(u.(u u) y)
[u.(u u)] # [y] -> y y
0 -> x.y.(y y)
Result = x.y.(y y)
このようにβ-redex は式の内側にあっても,β変換することができます.
lb> :p (x.y.x (f y))
Input = x.y.x (f y)
Tree = (x.y.x
#
(f%
|
y%))
(f y) を前のλ式の x.y.x の x の部分に入れてしまうと,y.(f y) となり,
自由だった (f y) の y が束縛されてしまいます.β変換はこれを禁止しています.
従って,この場合はβ変換できません.
しかし,前がλ式で表される関数で,形の上では後ろに適用してよい形に なっているのに関数適用できないのは,うまくありません.この場合は, まず,上に述べたα変換で前の束縛変数 y を,例えば,y2 に変換して おいてから,β変換の制約違反を解消したのちにβ変換を適用します.
(x.y.x (f y)) -> (x.y2.x (f y)) -> y2.(f y)
今回作成したインタープリタは明示的にα変換を行う機能は作成しませんでしたが, β変換に不都合なら自動的にα変換するようになっています.
lb> (x.y.x (f y))
Input = x.y.x (f y)
[x.y.x] # [f y] -> y102.(f y)
0 -> y102.(f y)
Result = y102.(f y)
前の式の変数 y が y102 に変わりましたね.このツールは新しい変数名を
作り出すのに,3ケタ以上の連番を使うようになっています.したがって,
変数名の衝突をさけるため,変数名の後ろに数字を付けるときは二けたで
押さえておいてください.
このようなα変換とβ変換を繰り返して,新たなλ式を作成していく過程で計算を 表そうと言うのがλ計算ですが,その説明に入る前に,これらの変換について,少し プログラマ向けの補足をしておきます.
α変換はプログラミング言語で言えば,
ということに対応しています.例えば C 言語で,次の二つの関数 my_square と my_square2 は同じの機能を持っています.関数定義のパラメータ名は,関数の内側と合わせる限りなんでもよい
int my_square(int x) {
return x*x;
}
int my_square2(int x2) {
return x2*x2;
}
このような同機能の関数は置き換えてよいというのがα変換です.
次にβ変換と自由変数のことも C 言語の例を使って説明しましょう.
int z = 10;
int f(int z) {
return g() + z;
}
int g() {
return z*z;
}
この例で関数 g の中の z は大域変数の z を指しているので,f(3) でも f(5) でも g は,10*10 = 100 を返すはずです.その結果,f(3) = 100 + 3 = 103, f(5)=100 + 5 = 105 となります. 一方,プログラミング言語の最適化の手法で,f の中の g を展開してしまうという技法があります.このようにすると,f は
z = 10;
int f(int z) {
return z*z + z; /* g() + z */
}
となり,z*z も f のパラメータの z になってしまい,もとのプログラムと意味が
変わってしまいます.β変換の制限は,このように意味が変わる変換は行わないという
制限になっています.これの意味を元のままに保とうと思えば,f のパラメータの z が
大域変数の z を隠さないように,名前を変えればよい訳です.例えば,
z = 10; int f(intのようにです.これがα変換に相当します.z2 ) { return z*z +z2 ; /* g() + z */ }
少し特殊な補足:動的束縛と静的束縛 (分かりにくければ飛ばして良いです)実は,プログラミング言語によっては,f が呼ばれる位置で,この z の意味が変わるという方式を採用している 場合もあります.この方式は変数の
動的束縛 と言われます.一方,C 言語などのように 変数を書いた場所によってそれがどれを指すか決まる方式を静的束縛 と言います.一般に 静的束縛の方が人間には分かりやすいと言われています.動的束縛が可能な言語の 代表としては LISP がありました.現在の COMMON LISP は静的束縛を原則としていて, 指示すれば動的束縛もできます.ちなみに, COMMON LISP がでる前の多くの LISP では 解釈実行時は動的束縛,コンパイルすると静的束縛というカオスな状況がありました. インタープリタでデバッグして動くことを確認した後,速度を上げるためにコンパイルすると 動かないという状況が発生していた訳です.
以上で,λ式の変換としてα変換とβ変換が定義されました.λ式の計算とは,β変換に
必要ならα変換を施して,β変換を繰り返し,もう,β変換ができなくなる形を得る
過程として定義します.つまり,β-redex が存在しない形です.β-redex が存在しない
λ式を,
計算の例
(((λx.λy.y) x) y) -> (λy.y y) -> y
(λg.λf.λx.(f ((g f) x)) λf.λx.(f (f x)))
-> λf.λx.(f ((λf.λx.(f (f x)) f) x))
-> λf.λx.(f (λx.(f (f x)) x))
-> λf.λx.(f (f (f x)))
この2番目のは何をやっているか分かりますでしょうか.二番目の後ろの項は,λf.λx. の後に,
x に f を2回適用した形になっています.それに最初のλ式を適用したら,結果として x に
f を3回適用した形になっています.右側に f と x をとって,x に f をn 回適用する
λ式があるとき,左側のλ式はそれを f の n+1 回の適用に書き換えると言う作用を持っています.
なんとなく計算が出来るような雰囲気がでてきたでしょう.このページではこういうことを
λ式のインタープリタを使って確かめながら学びます.
この節の目的は,λ式で帰納的関数が記述できることを実感することです. と言っても,その理論的な証明をするというのではなく,初歩のプログラミングで でてくるようないくつかの関数をλ式で記述してみようということです.こうやったら 再帰関数がλ式で書けるということが分かれば,教科書などで理論を追いかけていくときに ずいぶん楽になると思います.
λ式でプログラミングができることを実感するためには,(1)我々がよく目にするデータ型が 書けて,(2)その上の再帰関数が書けることを見て行けばよいと思います.と言うことで, ここでは,まず,論理値,自然数,リスト構造(木構造)などのデータ型をλ式が書くことが でき,その上に再帰関数が書けることを,例を使って示します.ここで示すデータ型も再帰関数の 表現方法もあくまで一例で,これでなければならないという訳ではありません.いろいろな バリエーションがあり得ます.
ここでは理屈と一緒に実際に動かしてみて,理屈を確かめながら勉強しますので, λ計算のインタープリタを起動して, システム組み込みの名前の定義ファイル は予め読み込んでおいてください.
irb(main):009:0> ltop
lb> :load "sys.def"
File "sys.def" loaded
lb> :s
Identifier(s):
S := x.y.z.(x z (y z))
K := x.y.x
I := x.x
B := x.y.z.(x (y z))
C := x.y.z.(x z y)
true := x.y.x
false := x.y.y
Y0 := x.(f (x x))
Y := f.(x.(f (x x)) x.(f (x x)))
is_zero := n.(n u.x.y.y x.y.x)
suc := n.f.x.(f (n f x))
pred := n.f.x.(n g.h.(h (g f)) u.x u.u)
plus := m.n.f.x.(m f (n f x))
pair := x.y.f.(f x y)
1st := p.(p x.y.x)
2nd := p.(p x.y.y)
nil := x.x.y.x
null := p.(p x.y.x.y.y)
lb>
上のような名前が予め定義されています.
まずは,論理値から説明していきます.
のようにλ式を3つ並べて,CONDITION の部分に,変換すると true か false になるような λ式を置けば,それが true のとき, THEN_PART に簡約され,false の時に ELSE_PART に簡約されます.したがって,この論理値の表現方法は if 文の 利用を可能にします.
次にこのような論理値の表現に対して,論理演算がλ式で書けることを示しておきます. まず,論理値を反転させる not ですが,これは not が次のような if 文で書けることに 気付けば簡単にかけます.
not b = if b=true then false else true
b=true は,b そのものを持ってくれば良いですね.true/false は if 文の条件式の 役割を果たすということを上で書きました.ということで,
not := b.(b false true)
です.実際にやってみましょう.
lb> not:=b.(b false true)
lb> not true
Input = b.(b x.y.y x.y.x) x.y.x
[b.(b x.y.y x.y.x)] # [x.y.x] -> x.y.x x.y.y x.y.x
0 -> x.y.x x.y.y x.y.x
[x.y.x] # [x.y.y] -> y.x.y.y
1 -> y.x.y.y x.y.x
[y.x.y.y] # [x.y.x] -> x.y.y
2 -> x.y.y
Result = x.y.y
lb> not false
Input = b.(b x.y.y x.y.x) x.y.y
[b.(b x.y.y x.y.x)] # [x.y.y] -> x.y.y x.y.y x.y.x
0 -> x.y.y x.y.y x.y.x
[x.y.y] # [x.y.y] -> y.y
1 -> y.y x.y.x
[y.y] # [x.y.x] -> x.y.x
2 -> x.y.x
Result = x.y.x
はい,確かに論理値は反転できました.ただし,この not は論理値以外が引数で与えられたときは,
必ずしも論理値を返すものではありません.
では次は or を作ってみましょう.or は
or a b = if a then true else b
です.したがって
or := a.b.(a true b)
とすればよいことがわかるでしょう.やってみましょう.
lb> or := a.b.(a true b)
lb> or true false
Input = a.b.(a x.y.x b) x.y.x x.y.y
[a.b.(a x.y.x b)] # [x.y.x] -> b.(x.y.x x.y.x b)
0 -> b.(x.y.x x.y.x b) x.y.y
[x.y.x] # [x.y.x] -> y.x.y.x
[b.(y.x.y.x b)] # [x.y.y] -> y.x.y.x x.y.y
1 -> y.x.y.x x.y.y
[y.x.y.x] # [x.y.y] -> x.y.x
2 -> x.y.x
Result = x.y.x
lb> or false false
Input = a.b.(a x.y.x b) x.y.y x.y.y
[a.b.(a x.y.x b)] # [x.y.y] -> b.(x.y.y x.y.x b)
0 -> b.(x.y.y x.y.x b) x.y.y
[x.y.y] # [x.y.x] -> y.y
[b.(y.y b)] # [x.y.y] -> y.y x.y.y
1 -> y.y x.y.y
[y.y] # [x.y.y] -> x.y.y
2 -> x.y.y
Result = x.y.y
(or true false) と (or false false) しか確かめませんでしたが,他の 組み合わせも確かめてみてください.
同じようなのりで,and や imply (ならば) も書けることは分かると思います.
今回作ったインタープリタでは,チャーチ数は,例えば,($3) のように, $ に続いて,数を入れれば自動的に作成できるようにしています. :p でチャーチ数の構造を見てみましょう.
lb> :p ($3)
Input = f.x.(f (f (f x)))
Tree = f.x.(f
|
(f
|
(f
|
x)))チャーチ数の 3 は,f が x に3回かかっていますね.
この数の体系でいろいろな演算が書けることを示します.まず最初に,これは演算と いうより述語ですが,与えられた自然数のλ式がゼロかどうか確かめる関数が書けることを示します.
数 n の表現は関数 f を貰って,それを次にもらうデータに n 回適用する関数ですから, 最初のデータとして true ,数 n の引数として入れる関数 f として,常に false を返す関数,u.false を 入れれば,($0) (u.false) true は,(u.false) が一度も実行されずに true が返り, ($2) (u.false) true など 0 以外では,最低一回はデータに u.false が適用されるために false が返ります.つまり
とやればよいはずです.やってみましょう.
lb> is_zero := n.((n u.false) true)
lb> :s
Identifier(s):
S := x.y.z.(x z (y z))
... 途中略
is_zero := n.(n u.x.y.y x.y.x)
lb> is_zero ($0)
Input = n.(n u.x.y.y x.y.x) f.x.x
[n.(n u.x.y.y x.y.x)] # [f.x.x] -> f.x.x u.x.y.y x.y.x
0 -> f.x.x u.x.y.y x.y.x
[f.x.x] # [u.x.y.y] -> x.x
1 -> x.x x.y.x
[x.x] # [x.y.x] -> x.y.x
2 -> x.y.x
Result = x.y.x trueの表現です
lb> is_zero ($1)
Input = n.(n u.x.y.y x.y.x) f.x.(f x)
[n.(n u.x.y.y x.y.x)] # [f.x.(f x)] -> f.x.(f x) u.x.y.y x.y.x
0 -> f.x.(f x) u.x.y.y x.y.x
[f.x.(f x)] # [u.x.y.y] -> x.(u.x.y.y x)
1 -> x.(u.x.y.y x) x.y.x
[u.x.y.y] # [x] -> x105.y.y
[x.x105.y.y] # [x.y.x] -> x105.y.y
2 -> x105.y.y
Result = x105.y.y α変換が起こっていますが false の表現です
lb> is_zero ($3)
Input = n.(n u.x.y.y x.y.x) f.x.(f (f (f x)))
[n.(n u.x.y.y x.y.x)] # [f.x.(f (f (f x)))] -> f.x.(f (f (f x))) u.x.y.y x.y.x
0 -> f.x.(f (f (f x))) u.x.y.y x.y.x
[f.x.(f (f (f x)))] # [u.x.y.y] -> x.(u.x.y.y (u.x.y.y (u.x.y.y x)))
1 -> x.(u.x.y.y (u.x.y.y (u.x.y.y x))) x.y.x
[u.x.y.y] # [x] -> x106.y.y
[u.x.y.y] # [x106.y.y] -> x.y.y
[u.x.y.y] # [x.y.y] -> x.y.y
[x.x.y.y] # [x.y.x] -> x.y.y
2 -> x.y.y
Result = x.y.y これも false です
次は1加える演算 add1 を作ってみます.これは自然数をとって自然数を返す関数ですから,
add1 :=n.f.x.(...)
のような形をしていると予想できましょう.自然数 n の表現 ($n) が関数 f とデータ x をとって, f を n 回 x に適用する関数であることを考えれば,その前に f と x をもらい,($n) を使って f を n 回 x に適用した後,さらに一回 f を適用した結果を返せばできます.つまり,
でできるはずです.やってみましょう.
lb> add1 := n.f.x.(f (n f x))
lb> add1 ($0)
Input = n.f.x.(f (n f x)) f.x.x
[n.f.x.(f (n f x))] # [f.x.x] -> f.x.(f (f.x.x f x))
0 -> f.x.(f (f.x.x f x))
[f.x.x] # [f] -> x.x
1 -> f.x.(f (x.x x))
[x.x] # [x] -> x
2 -> f.x.(f x)
Result = f.x.(f x)
lb> add1 ($3)
Input = n.f.x.(f (n f x)) f.x.(f (f (f x)))
[n.f.x.(f (n f x))] # [f.x.(f (f (f x)))] -> f.x.(f (f.x.(f (f (f x))) f x))
0 -> f.x.(f (f.x.(f (f (f x))) f x))
[f.x.(f (f (f x)))] # [f] -> x.(f (f (f x)))
1 -> f.x.(f (x.(f (f (f x))) x))
[x.(f (f (f x)))] # [x] -> f (f (f x))
2 -> f.x.(f (f (f (f x))))
3 -> f.x.(f (f (f (f x))))
Result = f.x.(f (f (f (f x))))
確かにできているようです.実は,add1 相当の関数は sys.def に suc という 名前で入っています.:s で定義をみてみると今入れた add1 と同じ定義が入っていることが 分かるでしょう.
通常,再帰関数の理論では,1加える関数と1引く関数を作って,足し算や掛け算は,これらから 再帰的な定義を使って作るのですが,チャーチの自然数の表現方法は,これらの関数, ついでに冪 nm までが再帰的定義を使わずに,次のように直接簡単に書けます.
fn (fm x) = fn+m x
が出来上がると言う訳です.
まず,3つの関数を定義します.
lb> plus := m.n.f.x.(m f (n f x))
lb> mult := m.n.f.(m (n f))
lb> power := m.n.(n m)
まずは, 2 + 3 から
lb> plus ($2) ($3)
Input = m.n.f.x.(m f (n f x)) f.x.(f (f x)) f.x.(f (f (f x)))
[m.n.f.x.(m f (n f x))] # [f.x.(f (f x))] -> n.f.x.(f.x.(f (f x)) f (n f x))
0 -> n.f.x.(f.x.(f (f x)) f (n f x)) f.x.(f (f (f x)))
[f.x.(f (f x))] # [f] -> x.(f (f x))
[n.f.x.(x.(f (f x)) (n f x))] # [f.x.(f (f (f x)))] -> f.x.(x.(f (f x)) (f.x.(f (f (f x))) f x))
1 -> f.x.(x.(f (f x)) (f.x.(f (f (f x))) f x))
[f.x.(f (f (f x)))] # [f] -> x.(f (f (f x)))
[x.(f (f x))] # [x.(f (f (f x))) x] -> f (f (x.(f (f (f x))) x))
2 -> f.x.(f (f (x.(f (f (f x))) x)))
[x.(f (f (f x)))] # [x] -> f (f (f x))
3 -> f.x.(f (f (f (f (f x)))))
4 -> f.x.(f (f (f (f (f x)))))
Result = f.x.(f (f (f (f (f x)))))
確かにf.x. の後ろに f が 2+3=5 個ついています.
次は,2*3 です.
lb> mult ($2) ($3)
Input = m.n.f.(m (n f)) f.x.(f (f x)) f.x.(f (f (f x)))
[m.n.f.(m (n f))] # [f.x.(f (f x))] -> n.f.(f.x.(f (f x)) (n f))
0 -> n.f.(f.x.(f (f x)) (n f)) f.x.(f (f (f x)))
[f.x.(f (f x))] # [n f] -> x.(n f (n f x))
[n.f.x.(n f (n f x))] # [f.x.(f (f (f x)))] -> f.x.(f.x.(f (f (f x))) f (f.x.(f (f (f x))) f x))
1 -> f.x.(f.x.(f (f (f x))) f (f.x.(f (f (f x))) f x))
[f.x.(f (f (f x)))] # [f] -> x.(f (f (f x)))
[f.x.(f (f (f x)))] # [f] -> x.(f (f (f x)))
2 -> f.x.(x.(f (f (f x))) (x.(f (f (f x))) x))
[x.(f (f (f x)))] # [x] -> f (f (f x))
[x.(f (f (f x)))] # [f (f (f x))] -> f (f (f (f (f (f x)))))
3 -> f.x.(f (f (f (f (f (f x))))))
4 -> f.x.(f (f (f (f (f (f x))))))
Result = f.x.(f (f (f (f (f (f x))))))
f.x. の後ろに f が 2*3=6個ついています.
最後は冪 23です.
lb> power ($2) ($3)
Input = m.n.(n m) f.x.(f (f x)) f.x.(f (f (f x)))
[m.n.(n m)] # [f.x.(f (f x))] -> n.(n f.x.(f (f x)))
0 -> n.(n f.x.(f (f x))) f.x.(f (f (f x)))
[n.(n f.x.(f (f x)))] # [f.x.(f (f (f x)))] -> f.x.(f (f (f x))) f.x.(f (f x))
1 -> f.x.(f (f (f x))) f.x.(f (f x))
[f.x.(f (f (f x)))] # [f.x.(f (f x))] -> x.(f.x.(f (f x)) (f.x.(f (f x)) (f.x.(f (f x)) x)))
2 -> x.(f.x.(f (f x)) (f.x.(f (f x)) (f.x.(f (f x)) x)))
[f.x.(f (f x))] # [x] -> x109.(x (x x109))
[f.x.(f (f x))] # [x109.(x (x x109))] -> x110.(x109.(x (x x109)) (x109.(x (x x109)) x110))
[f.x.(f (f x))] # [x110.(x109.(x (x x109)) (x109.(x (x x109)) x110))] -> x111.(x110.(x109.(x (x x109)) (x109.(x (x x109)) x110)) (x110.(x109.(x (x x109)) (x109.(x (x x109)) x110)) x111))
3 -> x.x111.(x110.(x109.(x (x x109)) (x109.(x (x x109)) x110)) (x110.(x109.(x (x x109)) (x109.(x (x x109)) x110)) x111))
[x109.(x (x x109))] # [x110] -> x (x x110)
[x109.(x (x x109))] # [x (x x110)] -> x (x (x (x x110)))
[x109.(x (x x109))] # [x110] -> x (x x110)
[x109.(x (x x109))] # [x (x x110)] -> x (x (x (x x110)))
[x110.(x (x (x (x x110))))] # [x111] -> x (x (x (x x111)))
[x110.(x (x (x (x x110))))] # [x (x (x (x x111)))] -> x (x (x (x (x (x (x (x x111)))))))
4 -> x.x111.(x (x (x (x (x (x (x (x x111))))))))
5 -> x.x111.(x (x (x (x (x (x (x (x x111))))))))
Result = x.x111.(x (x (x (x (x (x (x (x x111))))))))
α変換が起こって,変数名が変わってしまいましたが関数に相当する
変数 x が x.x111. の後ろに 23=8個ついて,データ x111 に適用されて
います.
チャーチの数の表現方法では,足し算,掛け算,冪演算など高等な演算が簡単に書けましたが,
直前で,1引く演算は難しいとは言いましたが,実は
一応,:p で構造を見てみましょう.
lb> :p pred
Input = n.f.x.(n g.h.(h (g f)) u.x u.u)
Tree = n.f.x.(((n
|||
||g.h.(h
|| |
|| (g
|| |
|| f)))
|u.x)
u.u)
うん,よくわかりませんが,自然数 n を g.h.(h (g f)) に適用したものを u.x と u.u に適用している訳ですね.ためしに,g.h.(h (g f)) の部分を H, u.x を a , u.u を b とおいて,n = ($4) くらいで, ($4) H a b がどんな形になるか確かめてみましょう.
lb> ($4) H a b
Input = f.x.(f (f (f (f x)))) H a b
[f.x.(f (f (f (f x))))] # [H] -> x.(H (H (H (H x))))
0 -> x.(H (H (H (H x)))) a b
[x.(H (H (H (H x))))] # [a] -> H (H (H (H a)))
1 -> H (H (H (H a))) b
2 -> H (H (H (H a))) b
Result = H (H (H (H a))) b
つまり,a が一番内側に入って,H がその外側に n 回取り囲んだものを b に適用する という形になります.
次にもう少し詳細に H の適用がどうなるか見てみましょう.
H := g.h.(h (g f)) として実際に適用結果がどうなるか見てみます.まず, 一番内側の H a です.ここで a は実際には u.x ですからそれも入れます.
lb> H := g.h.(h (g f))
lb> H u.x
Input = g.h.(h (g f)) u.x
[g.h.(h (g f))] # [u.x] -> h.(h (u.x f))
0 -> h.(h (u.x f))
[u.x] # [f] -> x
1 -> h.(h x)
Result = h.(h x)
つまり,何か関数 h をもらって,それを x に適用する形になります.次に,この形のλ式に H を適用するとどうなるか見てみましょう.この形とは, 関数 h をもらって,それを何かに適用するという形です.つまり,h.(h Something) です.
lb> H h.(h Something)
Input = g.h.(h (g f)) h.(h Something)
[g.h.(h (g f))] # [h.(h Something)] -> h.(h (h.(h Something) f))
0 -> h.(h (h.(h Something) f))
[h.(h Something)] # [f] -> f Something
1 -> h.(h (f Something))
2 -> h.(h (f Something))
Result = h.(h (f Something))
Something に f を適用して,その周りに再度 h.(h ...) のように囲んでいます.
段々見えてきました.まとめると,
このような H の性質を使って,最初の H は u.x に適用させることによって,単に x に変化させ,残りの n-1個の H を h.(h Something) に適用させることにより
H h.(h Something) => g.h.(h (g f)) h.(h Something) =>
h.(h (h.h Something) f) => h.(h (f Something))
ということで,f を n-1回適用する形を 作って,最後に h に u.u を入れ,f が x に n-1 回適用された形を作りだしていた 訳です.ちょっと,これは思いつける気がしませんが,分かったということで,記念に pred ($4) の実行過程と結果を見て終わりにしましょう.
lb> pred ($4)
Input = n.f.x.(n g.h.(h (g f)) u.x u.u) f.x.(f (f (f (f x))))
[n.f.x.(n g.h.(h (g f)) u.x u.u)] # [f.x.(f (f (f (f x))))] -> f.x.(f.x.(f (f (f (f x)))) g.h.(h (g f)) u.x u.u)
0 -> f.x.(f.x.(f (f (f (f x)))) g.h.(h (g f)) u.x u.u)
[f.x.(f (f (f (f x))))] # [g.h.(h (g f))] -> x.(g.h.(h (g f)) (g.h.(h (g f)) (g.h.(h (g f)) (g.h.(h (g f)) x))))
1 -> f.x.(x.(g.h.(h (g f)) (g.h.(h (g f)) (g.h.(h (g f)) (g.h.(h (g f)) x)))) u.x u.u)
[g.h.(h (g f))] # [x] -> h.(h (x f))
[g.h.(h (g f))] # [h.(h (x f))] -> h.(h (h.(h (x f)) f))
[g.h.(h (g f))] # [h.(h (h.(h (x f)) f))] -> h.(h (h.(h (h.(h (x f)) f)) f))
[g.h.(h (g f))] # [h.(h (h.(h (h.(h (x f)) f)) f))] -> h.(h (h.(h (h.(h (h.(h (x f)) f)) f)) f))
[x.h.(h (h.(h (h.(h (h.(h (x f)) f)) f)) f))] # [u.x] -> h.(h (h.(h (h.(h (h.(h (u.x f)) f)) f)) f))
2 -> f.x.(h.(h (h.(h (h.(h (h.(h (u.x f)) f)) f)) f)) u.u)
[u.x] # [f] -> x
[h.(h x)] # [f] -> f x
[h.(h (f x))] # [f] -> f (f x)
[h.(h (f (f x)))] # [f] -> f (f (f x))
[h.(h (f (f (f x))))] # [u.u] -> u.u (f (f (f x)))
3 -> f.x.(u.u (f (f (f x))))
[u.u] # [f (f (f x))] -> f (f (f x))
4 -> f.x.(f (f (f x)))
Result = f.x.(f (f (f x)))
はい,無事に ($3) = f.x.(f (f (f x))) になりました.
ここではチャーチの自然数の表現に対して,0 の判定,足し算,掛け算,冪演算,引き算ができることが分かりました.それにしても,1引く演算は難しかったです.
他の方法をとると,1の加減が簡単に表現できるものもあります.
今日,計算機は数値演算だけでなく多くの記号処理に使われています.そこで,ここでは そのような記号処理として,リストの基本演算がλ式で表現できることを示します.
リストの基本演算は,絞り込むと次の関数になります.
大雑把にいって,これに再帰定義機能が加わったのが初期のリスト処理言語 LISP です. 再帰定義機能は次の節で説明するので,この節では上の5つの関数がλ式で実現できることを 学習します.また,最後に,前節の最後で述べたように1引く演算を,これらの関数を 使って,少し分かりやすく書いてみます.
実はこれらは,"sys.def" に最初から入っています.
lb> :load "sys.def"
File "sys.def" loaded
lb> :s
Identifier(s):
S := x.y.z.(x z (y z))
K := x.y.x
I := x.x
B := x.y.z.(x (y z))
C := x.y.z.(x z y)
true := x.y.x
false := x.y.y
Y0 := x.(f (x x))
Y := f.(x.(f (x x)) x.(f (x x)))
is_zero := n.(n u.x.y.y x.y.x)
suc := n.f.x.(f (n f x))
pred := n.f.x.(n g.h.(h (g f)) u.x u.u)
plus := m.n.f.x.(m f (n f x))
pair := x.y.f.(f x y)
1st := p.(p x.y.x)
2nd := p.(p x.y.y)
nil := x.x.y.x
null := p.(p x.y.x.y.y)
それぞれを説明します.
null (pair a b) = (pair a b) x.false = x.false a b
となって,false が返ります.
a, b は自由変数としてこれのペアを作って,名前 aaa を付けておきます.
lb> aaa := pair a b
aaa の実体は次のようなλ式です.
lb> aaa
Input = x.y.f.(f x y) a b
[x.y.f.(f x y)] # [a] -> y.f.(f a y)
0 -> y.f.(f a y) b
[y.f.(f a y)] # [b] -> f.(f a b)
1 -> f.(f a b)
2 -> f.(f a b)
Result = f.(f a b)
つまり関数 f をもらって, (f a b) を返す式ですね.
1st をとってみます.
lb> 1st aaa
Input = p.(p x.y.x) (x.y.f.(f x y) a b)
[x.y.f.(f x y)] # [a] -> y.f.(f a y)
[p.(p x.y.x)] # [y.f.(f a y) b] -> y.f.(f a y) b x.y.x
0 -> y.f.(f a y) b x.y.x
[y.f.(f a y)] # [b] -> f.(f a b)
1 -> f.(f a b) x.y.x
[f.(f a b)] # [x.y.x] -> x.y.x a b
2 -> x.y.x a b
[x.y.x] # [a] -> y.a
3 -> y.a b
[y.a] # [b] -> a
4 -> a
Result = a
最初の要素になりました.
2nd をとってみます.
lb> 2nd aaa
Input = p.(p x.y.y) (x.y.f.(f x y) a b)
[x.y.f.(f x y)] # [a] -> y.f.(f a y)
[p.(p x.y.y)] # [y.f.(f a y) b] -> y.f.(f a y) b x.y.y
0 -> y.f.(f a y) b x.y.y
[y.f.(f a y)] # [b] -> f.(f a b)
1 -> f.(f a b) x.y.y
[f.(f a b)] # [x.y.y] -> x.y.y a b
2 -> x.y.y a b
[x.y.y] # [a] -> y.y
3 -> y.y b
[y.y] # [b] -> b
4 -> b
Result = b
nil の実体です.
lb> nil
Input = x.x.y.x
Result = x.x.y.x
nil が null でチェックできるか確かめます.
lb> null nil
Input = p.(p x.y.x.y.y) x.x.y.x
[p.(p x.y.x.y.y)] # [x.x.y.x] -> x.x.y.x x.y.x.y.y
0 -> x.x.y.x x.y.x.y.y
[x.x.y.x] # [x.y.x.y.y] -> x.y.x
1 -> x.y.x
Result = x.y.x
これは true を展開した形です.
pair を取ったものに対する null をチェックしてみます.
lb> null (pair a nil)
Input = p.(p x.y.x.y.y) (x.y.f.(f x y) a x.x.y.x)
[x.y.f.(f x y)] # [a] -> y.f.(f a y)
[p.(p x.y.x.y.y)] # [y.f.(f a y) x.x.y.x] -> y.f.(f a y) x.x.y.x x.y.x.y.y
0 -> y.f.(f a y) x.x.y.x x.y.x.y.y
[y.f.(f a y)] # [x.x.y.x] -> f.(f a x.x.y.x)
1 -> f.(f a x.x.y.x) x.y.x.y.y
[f.(f a x.x.y.x)] # [x.y.x.y.y] -> x.y.x.y.y a x.x.y.x
2 -> x.y.x.y.y a x.x.y.x
[x.y.x.y.y] # [a] -> y.x.y.y
3 -> y.x.y.y x.x.y.x
[y.x.y.y] # [x.x.y.x] -> x.y.y
4 -> x.y.y
Result = x.y.y
無事,false=x.y.y になりました.
前節で説明したチャーチ数から1引く関数 pred は,とても難しいものでした. もう一度,定義を書きますと,
でした.前節で予告していたように,pair を使って,もう少し分かりやすい, 1を減ずる関数を作ってみます.こちらは sub1 という名前で作りましょう.pred := n.f.x.(n g.h.(h (g f)) u.x u.u)
こちらも考え方自身は前と同じです.チャーチ数の ($n) は関数 f とデータ x を とって,x に f を n 回適用する機能を持ったλ式です.したがって,($(n-1)) を 作るには,そのうちの1回(初めの1回にしましょう)を無効にしてやれば良いのです. それには渡ってきたデータが1回目のデータかそれ以降かを区別できれば良いのです. x そのものを使う代わりに pair を使って,第1要素にタグを付けましょう.
f' = p.(もし (1st p) が true なら (pair false (2nd p)) を返す.
そうでないなら (pair true (f (2nd p))) を返す.
これらを組み立てると sub1 は次の定義になります.
wrap := x.(pair true x)
tuple := f.(p.((1st p) (pair false (2nd p)) (pair false (f (2nd p)))))
sub1 := n.f.x.(2nd (n (tuple f) (wrap x)))
では,動かしてみましょう.
予め,true, false などの定義を読み込んでおきます.以前,
定義した pred もこの中に入っています.
lb> :load "sys.def"
File "sys.def" loaded
次にここで書いた定義式を入力します.
面倒なのでコピー&ペーストしました.
lb> wrap := x.(pair true x)
lb> tuple := f.(p.((1st p) (pair false (2nd p)) (pair false (f (2nd p)))))
lb> sub1 := n.f.x.(2nd (n (tuple f) (wrap x)))
どのように定義されたか見てみましょう.
lb> :s
Identifier(s):
S := x.y.z.(x z (y z))
K := x.y.x
I := x.x
wrap := x.(x.y.f.(f x y) x.y.x x)
tuple := f.p.(p.(p x.y.x) p (x.y.f.(f x y) x.y.y (p.(p x.y.y) p)) (x.y.f.(f x y) x.y.y (f (p.(p x.y.y) p))))
sub1 := n.f.x.(p.(p x.y.y) (n (f.p.(p.(p x.y.x) p (x.y.f.(f x y) x.y.y (p.(p x.y.y) p)) (x.y.f.(f x y) x.y.y (f (p.(p x.y.y) p)))) f) (x.(x.y.f.(f x y) x.y.x x) x)))
B := x.y.z.(x (y z))
C := x.y.z.(x z y)
true := x.y.x
false := x.y.y
Y0 := x.(f (x x))
Y := f.(x.(f (x x)) x.(f (x x)))
is_zero := n.(n u.x.y.y x.y.x)
suc := n.f.x.(f (n f x))
pred := n.f.x.(n g.h.(h (g f)) u.x u.u)
plus := m.n.f.x.(m f (n f x))
pair := x.y.f.(f x y)
1st := p.(p x.y.x)
2nd := p.(p x.y.y)
nil := x.x.y.x
null := p.(p x.y.x.y.y)
sub1 は結構大きなλ式です.
3 から 1 引いてみます.
lb> sub1 ($3)
Input = n.f.x.(p.(p x.y.y) (n (f.p.(p.(p x.y.x) p (x.y.f.(f x y) x.y.y (p.(p x.y.y) p)) (x.y.f.(f x y) x.y.y (f (p.(p x.y.y) p)))) f) (x.(x.y.f.(f x y) x.y.x x) x))) f.x.(f (f (f x)))
[p.(p x.y.x)] # [p] -> p x.y.x
[x.y.f.(f x y)] # [x.y.y] -> y.f.(f x.y.y y)
[p.(p x.y.y)] # [p] -> p x.y.y
[x.y.f.(f x y)] # [x.y.y] -> y.f.(f x.y.y y)
[p.(p x.y.y)] # [p] -> p x.y.y
... 出力が膨大なため途中省略
18 -> f.x.(x101.y.y x119.y.y (f (f x)))
[x101.y.y] # [x119.y.y] -> y.y
19 -> f.x.(y.y (f (f x)))
[y.y] # [f (f x)] -> f (f x)
20 -> f.x.(f (f x))
Result = f.x.(f (f x))
f が2回 x にかかっていますので ($2) になっています.
1 から 1 引いてみます.
lb> sub1 ($1)
Input = n.f.x.(p.(p x.y.y) (n (f.p.(p.(p x.y.x) p (x.y.f.(f x y) x.y.y (p.(p x.y.y) p)) (x.y.f.(f x y) x.y.y (f (p.(p x.y.y) p)))) f) (x.(x.y.f.(f x y) x.y.x x) x))) f.x.(f x)
[p.(p x.y.x)] # [p] -> p x.y.x
[x.y.f.(f x y)] # [x.y.y] -> y.f.(f x.y.y y)
[p.(p x.y.y)] # [p] -> p x.y.y
[x.y.f.(f x y)] # [x.y.y] -> y.f.(f x.y.y y)
[p.(p x.y.y)] # [p] -> p x.y.y
... こちらでも出力が膨大なため途中省略
5 -> f.x.(x132.y.x132 f.(f x134.y.y x) f131.(f131 x136.y.y (f x)) x130.y.y)
[x132.y.x132] # [f.(f x134.y.y x)] -> y.f.(f x134.y.y x)
6 -> f.x.(y.f.(f x134.y.y x) f131.(f131 x136.y.y (f x)) x130.y.y)
[y.f.(f x134.y.y x)] # [f131.(f131 x136.y.y (f x))] -> f138.(f138 x134.y.y x)
7 -> f.x.(f138.(f138 x134.y.y x) x130.y.y)
[f138.(f138 x134.y.y x)] # [x130.y.y] -> x130.y.y x134.y.y x
8 -> f.x.(x130.y.y x134.y.y x)
[x130.y.y] # [x134.y.y] -> y.y
9 -> f.x.(y.y x)
[y.y] # [x] -> x
10 -> f.x.x
Result = f.x.x
f がまったくかからず x をそのまま出しているのでこれは ($0)です.
ちなみに,前の節の pred でやってみます.
lb> pred ($3)
Input = n.f.x.(n g.h.(h (g f)) u.x u.u) f.x.(f (f (f x)))
[n.f.x.(n g.h.(h (g f)) u.x u.u)] # [f.x.(f (f (f x)))] -> f.x.(f.x.(f (f (f x))) g.h.(h (g f)) u.x u.u)
0 -> f.x.(f.x.(f (f (f x))) g.h.(h (g f)) u.x u.u)
[f.x.(f (f (f x)))] # [g.h.(h (g f))] -> x.(g.h.(h (g f)) (g.h.(h (g f)) (g.h.(h (g f)) x)))
1 -> f.x.(x.(g.h.(h (g f)) (g.h.(h (g f)) (g.h.(h (g f)) x))) u.x u.u)
[g.h.(h (g f))] # [x] -> h.(h (x f))
[g.h.(h (g f))] # [h.(h (x f))] -> h.(h (h.(h (x f)) f))
[g.h.(h (g f))] # [h.(h (h.(h (x f)) f))] -> h.(h (h.(h (h.(h (x f)) f)) f))
[x.h.(h (h.(h (h.(h (x f)) f)) f))] # [u.x] -> h.(h (h.(h (h.(h (u.x f)) f)) f))
2 -> f.x.(h.(h (h.(h (h.(h (u.x f)) f)) f)) u.u)
[u.x] # [f] -> x
[h.(h x)] # [f] -> f x
[h.(h (f x))] # [f] -> f (f x)
[h.(h (f (f x)))] # [u.u] -> u.u (f (f x))
3 -> f.x.(u.u (f (f x)))
[u.u] # [f (f x)] -> f (f x)
4 -> f.x.(f (f x))
Result = f.x.(f (f x))
結構短く終わっています.
こちらの方式は,分かりやすいのですが,λ計算での性能は前の pred の方が格段によいですね.
実は,もう一つポピュラーな自然数の表現方法があります.それは true を 0 として, 自然数 n は,n 回,前に false を付けるのです.
という表現方法です.これだと is_zero, add1, sub1 は次のようになります.
もう,これについては詳しくは述べませんが,このページの姉妹ページ
では,コンビネータを使って,この表現方法が詳しく説明されています. 合わせて読むと,かなり,自然数の表現に慣れることができると思います.また, これは公理的集合論 ZFC での自然数の作り方とも共通する部分があります.
ここではλ式およびλ計算のメカニズムを使って再帰的定義が書けることを学びます. 前節までで,λ式で自然数が表現でき,また,0 の判定 is_zero, 1足す関数 suc, 1引く関数 pred がλ式で書けることが分かりましたので,これらを合わせると, 帰納関数が書けることが分かります.
λ式で再帰呼び出しを書こうとしたときの不安としては,λ式では関数に名前が付けられないので, 再帰呼び出しができないのじゃないだろうかということがあります. しかし,実は名前を付ける機能はあるのです.それはλ抽象の機能です. λ抽象 (v.Exp Exp2) はもともと,λ式 Exp の中で,λ式 Exp2 に v という名前を付ける機能です.
例えば,次のような foo という再帰関数を作ろうとしたとします.
foo := x.(if (Cond x) then (F1 x) else (F2 (foo (A x))))
ここで,if then else はλ式の構文ではありませんが,再帰関数の典型的な形を
想像していただくために敢えて,構文を無視して書いています.つまり,x がある条件
Cond を満たすときは (F1 x) を計算して返し,そうでないときは,x に A を施したものの
foo の値を計算し,それに対して F2 を適用した値を (foo x) の値とするという意味です.
右辺の foo をどうやって自分自身とバインディングするかというと,foo はもう一つ関数 g を 引数にとるようにして,別のλ式に,自分自身をその変数に入れてもらいます. 次のようにやります.
(f .x.(f f x)g .x.(if (Cond x) then (F1 x) else (F2 (g g (A x)))))
このようにすると左側のλ式のなかで f は右側のλ式に束縛され,さらに,それが g の 値として 右側のλ式の中に送られ,結果として再帰的呼び出しができることになります. 右のλ式は引数が関数 g の分,増えましたので,再帰呼び出しの部分も g を引数に入れること に注意してください.
実はこのテクニックはC言語でも使えます.C言語ではもともと再帰呼び出しができるので こんなことをやる必要はないのですが,ちょっと次のプログラムを見てください.関数ポインタを 使って,自分自身の引数に自分自身を送り込むのです.
#include <stdio.h>
int f(int (*g)(), int n) {
if (n == 0)
return 1;
else
return n*(*g)(g, n-1);
}
int main(void) {
printf("%d\n", f(f, 6));
return 0;
}
このプログラムはコンパイルして実行すると無事 6! = 720 を出力します. 先のλ式はこれと同じことをやっている訳です.
再帰呼び出しを実現する方法が分かったところで,何か例を書いてみましょう. 階乗計算はデータが巨大になるし,自然数の関数ばかりだと変わり映えがしないので, リスト処理の append を作ってみましょう.append は2つのリストを結合するもので, 再帰呼び出しができるなら,
append := x.y.((null x) y (pair (1st x) (append (2nd x) y)))
のように書けます. 上に述べたように関数引数 g を取るようにし,再帰呼び出し側ではその関数 g を 呼ぶようにします.再帰呼び出し側で引数にも g を加えることを忘れないようにしてください. 最初に append を2回呼び出す関数 invoke も作っておきます.
append := g.x.y.((null x) y (pair (1st x) (g g (2nd x) y)))
invoke := f.x.y.(f f x y)
実行してみましょう.
まず,append と invoke を定義します.
lb> append := g.x.y.((null x) y (pair (1st x) (g g (2nd x) y)))
lb> invoke := f.x.y.(f f x y)
まず基本の場合として,前の引数が nil のときを確かめます.
lb> invoke append nil b
Input = f.x.y.(f f x y) g.x.y.(p.(p x.y.x.y.y) x y (x.y.f.(f x y) (p.(p x.y.x) x) (g g (p.(p x.y.y) x) y))) x.x.y.x b
[p.(p x.y.x.y.y)] # [x] -> x x202.y.x203.y.y
[p.(p x.y.x)] # [x] -> x x204.y.x204
[x.y.f.(f x y)] # [x x204.y.x204] -> y.f.(f (x x204.y.x204) y)
[p.(p x.y.y)] # [x] -> x x205.y.y
[f.x.y.(f f x y)] # [g.x.y.(x x202.y.x203.y.y y (y.f.(f (x x204.y.x204) y) (g g (x x205.y.y) y)))] -> x.y.(g.x.y.(x x202.y.x203.y.y y (y.f.(f (x x204.y.x204) y) (g g (x x205.y.y) y))) g.x.y.(x x202.y.x203.y.y y (y.f.(f (x x204.y.x204) y) (g g (x x205.y.y) y))) x y)
0 -> x.y.(g.x.y.(x x202.y.x203.y.y y (y.f.(f (x x204.y.x204) y) (g g (x x205.y.y) y))) g.x.y.(x x202.y.x203.y.y y (y.f.(f (x x204.y.x204) y) (g g (x x205.y.y) y))) x y) x.x.y.x b
... 途中,うんざりする大量の出力
5 -> b
Result = b
無事,後ろの引数の b になりました.
今度は nil でないリスト同士を append してみます.
lb> invoke append (pair a nil) (pair b nil)
Input = f.x.y.(f f x y) g.x.y.(p.(p x.y.x.y.y) x y (x.y.f.(f x y) (p.(p x.y.x) x) (g g (p.(p x.y.y) x) y))) (x.y.f.(f x y) a x.x.y.x) (x.y.f.(f x y) b x.x.y.x)
[p.(p x.y.x.y.y)] # [x] -> x x206.y.x207.y.y
[p.(p x.y.x)] # [x] -> x x208.y.x208
[x.y.f.(f x y)] # [x x208.y.x208] -> y.f.(f (x x208.y.x208) y)
[p.(p x.y.y)] # [x] -> x x209.y.y
[f.x.y.(f f x y)] # [g.x.y.(x x206.y.x207.y.y y (y.f.(f (x x208.y.x208) y) (g g (x x209.y.y) y)))] -> x.y.(g.x.y.(x x206.y.x207.y.y y (y.f.(f (x x208.y.x208) y) (g g (x x209.y.y) y))) g.x.y.(x x206.y.x207.y.y y (y.f.(f (x x208.y.x208) y) (g g (x x209.y.y) y))) x y)
... 途中,うんざりする大量の出力
9 -> f.(f a f.(f b x.x.y.x))
Result = f.(f a f.(f b x.x.y.x))
何か結果がでました.一番後ろの x.x.y.x は nil です.
これが pair(a (pair b nil) と等しいかどうかすぐにはみてとれないので,
こちらも実行してみます.
lb> pair a (pair b nil)
Input = x.y.f.(f x y) a (x.y.f.(f x y) b x.x.y.x)
[x.y.f.(f x y)] # [a] -> y.f.(f a y)
[x.y.f.(f x y)] # [b] -> y.f.(f b y)
0 -> y.f.(f a y) (y.f.(f b y) x.x.y.x)
[y.f.(f b y)] # [x.x.y.x] -> f.(f b x.x.y.x)
[y.f.(f a y)] # [f.(f b x.x.y.x)] -> f.(f a f.(f b x.x.y.x))
1 -> f.(f a f.(f b x.x.y.x))
2 -> f.(f a f.(f b x.x.y.x))
Result = f.(f a f.(f b x.x.y.x))
上と同じようですね.ということで append が出来ました.
最後に再帰関数と不動点演算子との関係について述べておきます.
多くのプログラミング言語では関数に名前を付けることで,再帰呼び出しが可能になっています. 例えば,次の foo のようにです.
foo := x.(if (Cond x) then (F1 x) else (F2 (foo (A x))))
この式で右の
G :=g .x.(if (Cond x) then (F1 x) else (F2 (g (A x))))
そうすると,もとの再帰関数 foo は,次の式を満たします.
foo = G foo (*)
つまり,G の作用で動かないものになります.このように何かの作用 G で動かない
もの(この場合はλ式)を G の
ここで G は求めるものの要求を書いているので書く人自身がよく分かっていると思いますが, G に対する不動点,すなわち,G の要求を満たす再帰関数は簡単に見つかるでしょうか?
天下り式ですが,例えば,
Y := f.(x.(f (x x)) x.(f (x x)))
としてみます.そうすると,
Y G = (f.(x.(f (x x)) x.(f (x x))) G)
= (x.(G (x x)) x.(G (x x)))
= (G (x.(G (x x) x.(G (x x))))
= G (Y G)
ということで,foo = (Y G) は上の式 (*) を満たす解になります.このように元の
λ式 G に作用させることで,G の不動点を作り出すλ式を
lb> :p Y
Input = f.(x.(f (x x)) x.(f (x x)))
Tree = f.(x.(f
# |
# (x
# |
# x))
x.(f
|
(x
|
x)))
このように,x.(f (x x)) を x.(f (x x)) 自身に適用させる形になっています.そうすると, 前の式の (f (x x)) の x の中に x.(f (x x)) を入れますから,元の式の前に f を付ける 格好になります.したがって,.この式は止まりません.試しに Y と入力してみてください.
lb> Y
Input = f.(x.(f (x x)) x.(f (x x)))
[x.(f (x x))] # [x.(f (x x))] -> f (x.(f (x x)) x.(f (x x)))
0 -> f.(f (x.(f (x x)) x.(f (x x))))
[x.(f (x x))] # [x.(f (x x))] -> f (x.(f (x x)) x.(f (x x)))
1 -> f.(f (f (x.(f (x x)) x.(f (x x)))))
[x.(f (x x))] # [x.(f (x x))] -> f (x.(f (x x)) x.(f (x x)))
2 -> f.(f (f (f (x.(f (x x)) x.(f (x x))))))
[x.(f (x x))] # [x.(f (x x))] -> f (x.(f (x x)) x.(f (x x)))
3 -> f.(f (f (f (f (x.(f (x x)) x.(f (x x)))))))
[x.(f (x x))] # [x.(f (x x))] -> f (x.(f (x x)) x.(f (x x)))
4 -> f.(f (f (f (f (f (x.(f (x x)) x.(f (x x))))))))
... 沢山の出力があって,変換階数 40 回の制限で止まり,
f が沢山適用された式を出力する
Result = f.(f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (x.(f (x x)) x.(f (x x)))))))))))))))))))))))))))))))))))))))))))
こんな感じです.この不動点演算子 Y を単独で使うと,このように止まりませんが, 今回提供しているλ式のインタープリタのデフォルトの変換戦略(:all , 一回に見つかった すべてのβ-redex を簡約する)では, (Y G) は,G できちんと条件式を書けば停止して正しい答えがでます.なぜかというと条件文 の部分が簡約されると,成立しない側の式が消えることがあり,その中に Y が入っていると, 無限に変換される部分が捨て去られるからです.
やってみましょう.
自然数 ($n) をとり,n 個だけ 記号 a を並べたリストを返す関数を作ってみます.
G := g.n.((is_zero n) nil (pair a (g (pred n))))
と定義して,(Y G) ($2) を実行してみます.
lb> G := g.n.((is_zero n) nil (pair a (g (pred n))))
lb> (Y G) ($2)
Input = f.(x.(f (x x)) x.(f (x x))) g.n.(n.(n u.x.y.y x.y.x) n x.x.y.x (x.y.f.(f x y) a (g (n.f.x.(n g.h.(h (g f)) u.x u.u) n)))) f.x.(f (f x))
[x.(f (x x))] # [x.(f (x x))] -> f (x.(f (x x)) x.(f (x x)))
[n.(n u.x.y.y x.y.x)] # [n] -> n u.x.y.y x.y.x
... 途中,凄まじい出力なので省略
10 -> f.(f a f.(f a x108.x109.y.x109))
Result = f.(f a f.(f a x108.x109.y.x109))
a が二つ見えますので,a を二つ並べたリストのように見えます.
確かめてみましょう.
lb> (pair a (pair a nil))
Input = x.y.f.(f x y) a (x.y.f.(f x y) a x.x.y.x)
[x.y.f.(f x y)] # [a] -> y.f.(f a y)
[x.y.f.(f x y)] # [a] -> y.f.(f a y)
0 -> y.f.(f a y) (y.f.(f a y) x.x.y.x)
[y.f.(f a y)] # [x.x.y.x] -> f.(f a x.x.y.x)
[y.f.(f a y)] # [f.(f a x.x.y.x)] -> f.(f a f.(f a x.x.y.x))
1 -> f.(f a f.(f a x.x.y.x))
2 -> f.(f a f.(f a x.x.y.x))
Result = f.(f a f.(f a x.x.y.x))
α変換すると同じですね.
以上,無事に (Y G) で不動点となる関数が求まっていました.しかし, この定義は変換戦略を :innermost にすると,延々と Y の部分を変換するため 止まりません.
このような不動点演算子は他にも沢山あります.Y より性質の良いものも いろいろ調べられていますので,皆さん,他の成書をあたってみて,調べてみてください.
以上で,再帰関数に関する話題は終わりです.
今まで,β変換,そして,それを妨げる変数名の問題があったときのα変換に ついて話してきましたが,λ式による計算のモデル化ではその他の変換も 考察されています. その中で比較的よく言及されるものとしてη変換があります.
η変換は関数の外延性,つまり,すべての値に対して,同じ値を返す二つの関数は 等しいということに基づく変換です.具体的には次のような変換です.
ただし,x は Exp の中で自由変数では無い
この左辺は何か式 E を受け取ると,β変換が行われ,Exp E を返します. 一方,右辺は E をとると,Exp E となり両者は一致します.そこで,この 二つは同等であるとするのです.
今回のインタープリタでもη変換は組み込んでありますが,最初は OFF に してあります.コマンド :eta を投入すると,η変換の機能を ON にできます.
Result = x.(Exp x)
lb> :eta
Eta mode = true
lb> x.(Exp x)
Input = x.(Exp x)
[x.(Exp x)] # [*Eta*] -> Exp
0 -> Exp
Result = Exp
上に書いたことが動いていることを示しただけなので面白くないかもしれませんが,
とにかくη変換を機能させることはできるようになります.η変換を組み込むと,α変換,β変換だけより多くのλ式の同等性を示せるのですが 次に述べる,λ計算が持っていたチャーチ・ロッサーの性質が無くなってしまいます. チャーチ・ロッサーの性質は計算結果の,α変換を除いての一意性を保証するもの なのでとても重要な性質なのです.
以上,η変換については,その規則と,チャーチ・ロッサーの性質との関連について だけ述べておきます.
チャーチ・ロッサーの定理についてもお話だけです.
チャーチ・ロッサーの定理は次のような定理です.
P を任意のλ式とする.もし,P から Q に0 回以上の α変換とβ変換で行けて, かつ,P から R にも 0 回以上の α変換とβ変換で行けるなら, あるλ式 S があり,Q からも,R からも 0 回以上の α変換とβ変換で S に行くことができる.
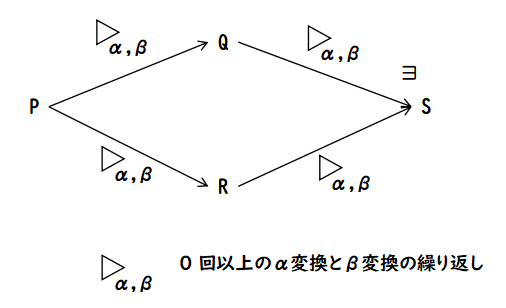
これは合流性とも言われ,正規形の一意性を保証する大切な性質です. なぜなら,もしあるλ式 P が二つの正規形 Q と R を持つなら,その二つから α変換とβ変換を 0 回以上繰り返して,共通のλ式 S に行けなければ ならないのですが,正規形は,β-redex を持たないので,α変換で両者は S に到達しなければならないのです.したがって,P から到達した二つの 正規形 Q と R はα変換で移りあえ,束縛変数名の違いを除けば同等であると いうことになります.
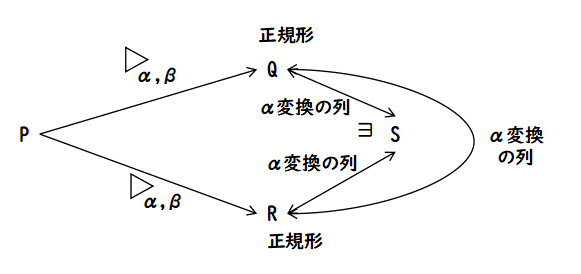
一般に変換規則を持つ系でチャーチ・ロッサーの定理が成り立つとき,その系は チャーチ・ロッサー性を持つとか,合流性を持つと言います.λ計算が チャーチ・ロッサーの定理は結構面倒です.ここでは,λ計算がα変換とβ変換に 限るとこのような合流性をもつことだけは覚えておいてください.
前節ではλ計算が,α変換とβ変換に限れば,チャーチロッサー性を持ち, 正規形が存在するなら,それは束縛変数の名前を除いて一意に決ることを 学習しました.では,β-redex が沢山あるときは,それらの変換はどんな 順序で実施すればよいでしょう?
例を吟味しながら話を進めましょう.下の「システム組み込みの名前の定義ファイル」 に定義された名前を使って説明していきますので,それをファイル"sys.def"として 保存して,インタープリタに :load コマンドで読み込んでおいてください.
lb> :load "sys.def"そして,λ式 (x.y.x A Y) を :p で表示してみてください.
lb> :p (x.y.x A Y)
Input = x.y.x A f.(x.(f (x x)) x.(f (x x)))
Tree = ((x.y.x
|#
|A%)
f.(x.(f
# |
# (x
# |
# x))
x.(f
|
(x
|
x))))
はい,# で結ばれた対が二つありますから,このλ式には二つのβ-redex がありますね.
後ろの方は不動点演算子 Y の中にあります.これは良く知られているように止まりません.
試しに,Y だけ打ち込んでみてください.
lb> Y
Input = f.(x.(f (x x)) x.(f (x x)))
[x.(f (x x))] # [x.(f (x x))] -> f (x.(f (x x)) x.(f (x x)))
0 -> f.(f (x.(f (x x)) x.(f (x x))))
[x.(f (x x))] # [x.(f (x x))] -> f (x.(f (x x)) x.(f (x x)))
1 -> f.(f (f (x.(f (x x)) x.(f (x x)))))
[x.(f (x x))] # [x.(f (x x))] -> f (x.(f (x x)) x.(f (x x)))
2 -> f.(f (f (f (x.(f (x x)) x.(f (x x))))))
[x.(f (x x))] # [x.(f (x x))] -> f (x.(f (x x)) x.(f (x x)))
3 -> f.(f (f (f (f (x.(f (x x)) x.(f (x x)))))))
[x.(f (x x))] # [x.(f (x x))] -> f (x.(f (x x)) x.(f (x x)))
... 途中略
Result = f.(f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (x.(f (x x)) x.(f (x x)))))))))))))))))))))))))))))))))))))))))))
はい,変換回数 40 回の制限で止まってくれましたが,これは内部に f の適用を次々に
付けて行って,止まらないλ式です.
しかし,λ式 (x.y.x A Y) の最初のβ-redex (x.y.x A) をβ変換し,y.A に簡約化すると, 全体の式は (y.A Y) になり,もう一度,Y の中でなく,この部分をβ変換すると A になり, もうβ変換できなくなります.つまり,Y の部分が落ちてしまった訳です.
このようにβ-redex の選び方により,同じλ式が止まったり,止まらなかったりします.
一般に,どのβ-redex から変換するかという選択方法を
lb> (x.y.x A Y)
Input = x.y.x A f.(x.(f (x x)) x.(f (x x)))
[x.y.x] # [A] -> y.A
[x.(f (x x))] # [x.(f (x x))] -> f (x.(f (x x)) x.(f (x x)))
0 -> y.A f.(f (x.(f (x x)) x.(f (x x))))
[x.(f (x x))] # [x.(f (x x))] -> f (x.(f (x x)) x.(f (x x)))
[y.A] # [f.(f (f (x.(f (x x)) x.(f (x x)))))] -> A
1 -> A
Result = A
実行結果を見てもらうと分かるのですが,Y の中は2回実行されているのですが,
そのうちに,x.y.x の部分も次々に適用されていき,2回目に Y を切り捨てて
しまうので,もうβ変換できない正規形に落ち着くのです.
本ツールでは,これが止まらない変換戦略も持っています.それは,:innermost です. この変換戦略では,λ式は内側から変換されていき,β-redex があっても,その内側で 変換が行われたら,そのβ-redex は適用されません.その内側で変換がないときだけ, そのβ-redex が適用されます.したがって,Y の部分が毎回変換されて止まらなくなります. 変換戦略を変えるには,コマンド :strat を投入すると,3つの変換戦略を順に選んでいけます.
lb> :strat
Reduction mode = innermost
lb> (x.y.x A Y)
Input = x.y.x A f.(x.(f (x x)) x.(f (x x)))
[x.y.x] # [A] -> y.A
[x.(f (x x))] # [x.(f (x x))] -> f (x.(f (x x)) x.(f (x x)))
0 -> y.A f.(f (x.(f (x x)) x.(f (x x))))
[x.(f (x x))] # [x.(f (x x))] -> f (x.(f (x x)) x.(f (x x)))
1 -> y.A f.(f (f (x.(f (x x)) x.(f (x x)))))
[x.(f (x x))] # [x.(f (x x))] -> f (x.(f (x x)) x.(f (x x)))
2 -> y.A f.(f (f (f (x.(f (x x)) x.(f (x x))))))
[x.(f (x x))] # [x.(f (x x))] -> f (x.(f (x x)) x.(f (x x)))
... 途中略
(f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (x.(f (x x)) x.(f (x x)))))))))))))))))))))))))))))))))))))))))))
Result = y.A f.(f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (f (x.(f (x x)) x.(f (x x)))))))))))))))))))))))))))))))))))))))))))
変換戦略を :innermost にして,(x.y.x A Y) を入力すると,まず,(x.y.x A) の部分と
Y が両方ともβ変換されます.Y は Y' に変換されたとすると,Y' も止まらない
λ式ですから,次の回以降の変換で (y.A Y') の部分の Y' が延々と変換されてしまいます.
このツールにはもう一つの戦略 :outermost が組み込まれていて,こちらは, 外側のβ-redex から変換されていきます.この戦略でも上の例は止まるのですが, :all の方が一度に変換する分,早く正規形にたどり着きます.
これらの戦略は独自といいましたが,一般には次のような戦略が紹介されています. ここの :innermost は,下の Applicative order に近いです.つまり,関数適用の 変換より,その引数が先に変換されるという部分が共通しています.しかし,Applicative order は,右側のβ-redex が先と書いてありましたので,ここの :innermost は,左右は 同時期に変換するというところが違います.ここらあたりは世の中の標準の戦略を実装 していなくて申し訳ないですが,各自で実装してみるのも勉強になると思います.尚, 下に書いた各戦略の具体的内容はそれぞれの文献を参照してみてください.
以上で,説明は終わります.後はプログラムリストと参考文献です.
利用には,「簡単な演算子順位法によるパーサー in Ruby」の パーサーの掲載リスト(Version 0.96 2019.02.24 以降)が必要です. 詳細は,「ちょっと動かしてみる」か 「簡易λ式インタープリタの機能の説明」 を見てください.それと,上のパーサーへのリンクは,そちらのページのローディングに 時間がかかると,きちんとプログラムリストのところに位置づけられないことがあります. そのような場合はもう一度リンクをクリックしなおしてみてください.
# Simple Lambda Calculus Interpreter
# Version 0.83 2019.02.24 by Akihiko Koga
$sop_ops[:"."] = [".", 1250, :xfy] # note that it is less than " "
$sop_ops[:":="] = [":=", 1600, :xfy]
$sop_ops[:":lim"] = [":lim", 200, :fy]
$sop_ops[:":load"] = [":load", 1500, :fy]
$sop_ops[:":church"] = ["$", 200, :fy] # ($2) is f.x.(f (f x))
$sop_ops[:":assign"] = ["//", 1500, :xfy] # e.g., Exp//(var=Exp2)
$sop_ops[:"="] = ["=", 1300, :xfy]
$sop_ops[:":p"] = [":p", 1800, :fy]
$lb_name_no = 100
$lb_limit = 40
$lb_ids = {}
$lb_result = "dummy"
$lb_reduction_mode = :all # or :innermost, :outermost
$lb_reductions = []
$lb_interactive_mode = false
$lb_verbose_mode = true
$lb_eta_mode = false
$lb_sys_function = {
# if an operator symbol is defined here,
# exp = [symbol, ...] is expanded to $ib_sys_function[symbol].call(exp)
:":church" => lambda {|x|
r = (1..x[1].to_s.to_i).inject("x") {|a, b| [:"#apply#", "f", a]}
[:".", "f", [:".", "x", r]]
},
:":assign"=> lambda {|x| # [:assign, exp, [:"=", var, exp2]]
if x[2][0] == :"=" then
lb_assign(lb_expand(x[1]), x[2][1], lb_expand(x[2][2]))
else
lb_expand(x[1])
end
},
}
"S := x.y.z.((x z) (y z))
K := x.y.x
I := x.x
".split("\n").each {|x|
if x != "" then y = sop_parse(x); $lb_ids[y[1]] = y[2]; end
}
$lb_commands = sop_new_commands( {
":verbose" => sop_gen_toggle("$lb_verbose_mode"),
":strat" => sop_gen_toggle("$lb_reduction_mode", nil, [:all, :innermost, :outermost]),
":o" => sop_gen_toggle("$lb_interactive_mode"),
":eta" => sop_gen_toggle("$lb_eta_mode"),
":clear" => lambda {|input, code|
$lb_ids = {}; printf(" Identifiers all cleared\n")},
":s" => lambda {|input, code|
printf(" Identifier(s):\n")
$lb_ids.each {|d| printf(" %s := ", d[0]); sop_print(d[1]) }},
:":=" => lambda {|inout, code|
$lb_result = $lb_ids[code[1]] = lb_expand(code[2])},
:":lim" => lambda {|inout, code|
$lb_limit =code[1].to_s.to_i
printf(" Translation limit seto to %d\n", $lb_limit)},
:":load" => lambda {|inout, code|
sop_load(code[1].gsub("\"", ""), $lb_commands)},
:":p" => lambda {|inout, code|
$lb_result = code2 = lb_expand(code[1])
printf(" Input = "); sop_print(code2)
printf(" Tree = "); lb_print_tree(code2, 10); printf("\n")},
:else => lambda {|inout, code|
code = lb_expand(code)
printf("Input = "); sop_print(code)
cont = false
$lb_limit.times {|i|
$lb_reductions = []
code2 = lb_trans1(code, $lb_reduction_mode)
if code2 == code then
break
end
if $lb_verbose_mode || $lb_interactive_mode then
$lb_reductions.each {|r|
printf(" ["); sop_print(r[0], false); printf("] # [");
sop_print(r[1], false); printf("] -> ");
sop_print(r[2], false); printf("\n");
}
printf("%4d -> ", i); sop_print(code2)
end
code = code2
if $lb_interactive_mode && !cont then
printf("Enter, c, q ?: ")
com = readline.strip
if com == "q" then break
elsif com == "c" then
cont = true
else
end
end
}
$lb_result = code
printf("Result = "); sop_print($lb_result)
},
})
def ltop
sop_top("Welcome to Simple Lambda Interpreter\n",
"Bye\n", "lb> ", $lb_commands)
end
def lb_free(exp)
if exp.class != Array then [exp]
elsif exp[0] == :"." then
lb_free(exp[2]) - [exp[1]]
else
lb_free(exp[1]) | lb_free(exp[2])
end
end
def lb_assign(exp, var, exp2)
lb_assign2(exp, var, exp2, lb_free(exp2))
end
def lb_assign2(exp, var, exp2, fvars)
if exp == var then exp2
elsif exp.class != Array then exp
elsif exp[0] == :"." then
if exp[1] == var then exp
elsif fvars.index(exp[1]) then
var2 = lb_new_name(exp[1])
exp = [:".", var2, lb_assign2(lb_rename(exp[2], exp[1], var2),
var, exp2, fvars)]
else
[:".", exp[1], lb_assign2(exp[2], var, exp2, fvars)]
end
else
[exp[0], lb_assign2(exp[1], var, exp2, fvars),
lb_assign2(exp[2], var, exp2, fvars)]
end
end
def lb_new_name(name)
$lb_name_no += 1; name + $lb_name_no.to_s
end
def lb_rename(exp, name1, name2)
if exp == name1 then name2
elsif exp.class != Array then exp
elsif exp[0] == :"." then
if exp[1] == name1 then
exp
else
[exp[0], exp[1], lb_rename(exp[2], name1, name2)]
end
else
[exp[0], lb_rename(exp[1], name1, name2), lb_rename(exp[2], name1, name2)]
end
end
def lb_expand(code)
if code == ":current" then return $lb_result end
x = $lb_ids[code]
if x != nil then code = x end
if code.class != Array then
code
elsif $lb_sys_function[code[0]] then
$lb_sys_function[code[0]].call(code)
elsif code[0] == :"." then
[code[0], code[1], lb_expand(code[2])]
else
code.map {|x| lb_expand(x)}
end
end
def lb_trans1(exp, mode=:all)
if exp.class != Array then exp
elsif exp[0] == :"#apply#" then
if exp[1][0] == :"." then
# beta redex
exp1 = exp[1][2]; var = exp[1][1]; exp2 = exp[2]
if [:all, :innermost].index(mode) then
exp1 = lb_trans1(exp1, mode); exp2 = lb_trans1(exp2, mode)
end
if mode == :innermost && (exp1 != exp[1][2] || exp2 != exp[2]) then
result = [:"#apply#", [:".", var, exp1], exp2]
else
result = lb_assign(exp1, var, exp2)
$lb_reductions.push([[:".", var, exp1], exp2, result])
end
result
else
# non-redex application
[exp[0], lb_trans1(exp[1], mode), lb_trans1(exp[2]), mode]
end
else
# lambda abstraction
if $lb_eta_mode && exp[2][0] == :"#apply#" && exp[1] == exp[2][2] &&
!lb_free(exp[2][1]).index(exp[1]) then
$lb_reductions.push([exp, "*Eta*", exp[2][1]])
exp[2][1]
else
[exp[0], exp[1], lb_trans1(exp[2], mode)]
end
end
end
def lb_print_tree(exp, depth=0, bars1=[], bars2=[], bounds=[])
if exp.class != Array then
printf("%s", exp.to_s)
if !bounds.index(exp) then printf("%") end
false
elsif exp[0] == :"#apply#" then
nl = false
bars1b = bars1; bars2b = bars2
if exp[1][0] == :"." then bars1b = [depth+1]+bars1
else bars2b = [depth+1]+bars2 end
printf("(")
if lb_print_tree(exp[1], depth+1, bars1b, bars2b, bounds) == false then
printf("\n"); nl = true
lb_indent(depth+2, bars1b, bars2b)
printf("\n")
end
if nl == false then printf("\n"); nl = true end
lb_indent(depth+1, bars1, bars2)
lb_print_tree(exp[2], depth+1, bars1, bars2, bounds)
printf(")")
nl
else
# lambda abstraction
printf("%s.", exp[1])
lb_print_tree(exp[2], depth+exp[1].to_s.length+1, bars1, bars2,
[exp[1]] + bounds)
end
end
def lb_indent(n, bars1, bars2)
n.times {|i|
printf("%s", bars1.index(i)? "#" :(bars2.index(i)? "|" : (" ")))
}
end
S := x.y.z.((x z) (y z)) K := x.y.x I := x.x B := x.y.z.(x (y z)) C := x.y.z.(x z y) true := x.y.x false := x.y.y Y0 := x.(f (x x)) Y := f.(Y0 Y0) is_zero := n.((n u.false) true) suc := n.f.x.(f (n f x)) pred := n.f.x.(n (g.h.(h (g f))) (u.x) (u.u)) plus := m.n.f.x.(m f (n f x)) pair := x.y.f.(f x y) 1st := p.(p true) 2nd := p.(p false) nil := x.true null := p.(p (x.y.false))
上が最近です.
λ計算についてはインターネット上にも沢山のレクチャーノートが見つかると思います. 例えば,私は次のドキュメントを見つけました.
計算機(主にソフトウェア)の話題 へ
圏論を勉強しよう へ
束論を勉強しよう へ
半群論を勉強しよう へ
ホームページトップ(Top of My Homepage)