
この2週間位,Forth っぽい言語のインタープリタをいくつか作って遊んで いた.本当は,何か他のシステムに組み込んで,機能拡張用のスクリプト言語として 使えればよいなと思いつつ,作っていたのだが,今のところ,「今後はこれを使って行こう」と いう気にまではならなかったので,ただ,遊んでいたというだけである.
でも,ただ遊んでいただけでは
今後に繋がらないので,考えたこと,調べたこと,測定してみたことなどをまとめておくことにした.タイトルも,「〇〇を作ってみた」というホームページはよくあるので,
「作ってみた
言い忘れたが,Forth は 1970 年代に公開された,
今回,5つか6つ作ったが(そのうち3つくらいは ruby を使った原理実験),最後に作ったものは次のような言語である.
この言語の実装自体は公開していない.どちらかと言えば失敗作に近いので,ソースプログラム そのものを公開するより,仕様,その仕様での使い勝手,実行速度や処理系の各部分の 規模の測定,短く作るためにはどうすればよいかの考察などが価値があると思ったので, ここにはそういう結果を載せた.
ここでは,今後の言語設計や言語処理系の作成の参考になるように,
まず,ここで作った言語の仕様を述べる.Forth に似ているけど,Forth ではない. 似て非なるもので申し訳ない.Forth について知りたい人は 参考文献にドキュメントや 処理系の探し方を書いたので参照してほしい.
Program ::= (Definition | Statement) ...
Definition ::= def Word Statement ... ;
Statement ::= Word | String | Integer | IfStatement |
WhileStatement | BlockStatement
IfStatement ::= if Statement Statement Statement
WhileStatement ::= while Statement Statement
BlockStatement ::= { Statement ... }
注意
・「...」は直前のものの 0 個以上の繰り返し
・String は " から始まって " で終わる文字列.ただし," を入れたいときは
その前に \ を入れる
・Integer は,数字の列で,先頭に + あるいは - が1個ついても良い
・Word は,{, } 以外の文字列で String, Integer, Real でないもの
(以下の実装ではなんとなく :, ; は1文字でワードとしている)
・関数定義は def から始まるようにしてあるが,Forth と同様に : も使える
ようにしてある.ただ Forth と区別がつけにくくなるのでここでは def で書く.
・// から行末まではコメントとして無視する
どんな言語か感じをつかめるように簡単な例題をあげておく.
def fact // argument is given as a number on the stack topif {0th 2 <} { pop 1 } { 0th 1 -fact * }; def fib // argument is given as a number on the stack topif {0th 2 <} { pop 1 } { {0th 1 -fib } {swap 2 -fib } + }; def start 10fib . cr;
デフォルトでは start という関数から始まるように設定してある. 上のプログラムでは fib だけしか起動されない.fact はおまけで書いてあるだけである. ところどころ,{, } が入っているが,これは単語を続けて書くと見にくくなるので, 文をブロック化できる機能を使って,意味的な単位を区切るためにも使っている. コンパイルすればこれらの括弧は消えるのでオーバーヘッドはない.空白や改行は単に 単語と単語の間を区切る意味しか持たないので,一行に続けて書いても構わない.
このプログラミング言語で書いたプログラムが実行される基本的な環境は次のように 1つのデータスタックがあり,ここには整数あるいはアドレスが置かれる,もう一つ, 名前の表があり,ここには関数やグローバル変数が置かれる.簡単のため,グローバル変数は $が先頭についた文字列とする.
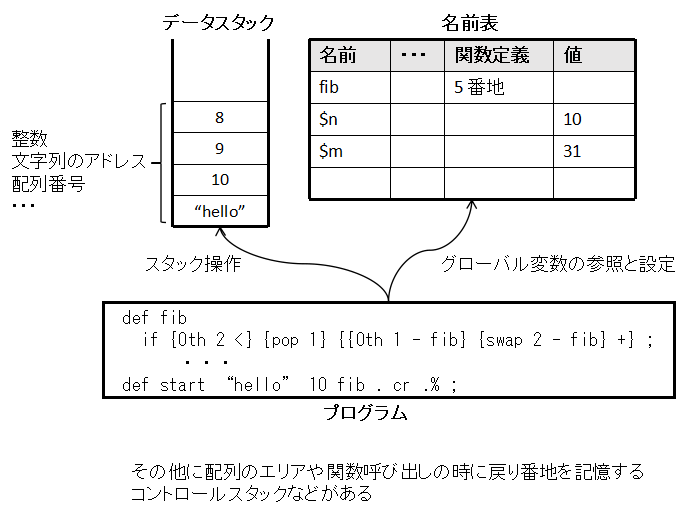
例えば,上の例の fib では,スタックトップに引数が与えられることを想定していて, それを 0th でコピーしてスタックに積み,それと 2 を比較して,2 が大きければ, if 文の二番目のブロック {pop 1} にいき,スタップトップをポップして,その代わりに fib の値である 1 を積む.
もし,2 との比較でスタックトップが 2 以上なら,3番目の ブロックを実行する,といった具合に計算は進む.この3番目のブロックには, 2か所に fib が表れているが,これらは再帰呼び出しである.あと,サンプルに 現れる文で,想像がつきにくいものとしては,「.」はスタックトップの数をポップして 表示し,「cr」は改行を出力する文である.
上に書いた図の右側にあるのは,プログラム中の 名前を管理する表で,グローバル変数はここで管理される.プログラムのコンパイル結果なども ここにあるが,ユーザが認識するのはほぼグローバル変数だけである.プログラムの中でグローバル変数への値の出し入れをする組み込みの関数が用意されている.その他にも配列を管理する 領域などがあるが,煩雑になるので,ここでの説明はこれくらいにしておく.
次に組み込みの関数や構文の意味について簡単に説明しておく.
組み込みのワード(Word)
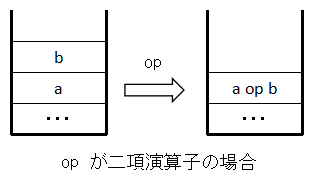
また,演算子が not や isqrt のように一項であるときはスタックは次のようになる.
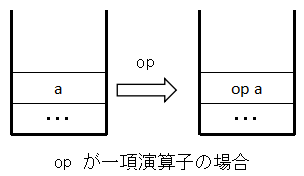
論理値に関しては,偽は 0,真はそれ以外とする. not は論理的な否定を返し,isqrt は整数の範囲での平方根を返す.
$a @ // 変数 $a の変数番号がスタックから取り除かれ,
// その代わりに $a の値をスタックトップにプッシュする
10 $a ! // 変数 $a に 10 を入れる.スタックは 10 の部分まで
// 取り除かれた状態になる.
100 array // 整数が 100 個入る配列を生成し,その配列番号をスタック
// トップにおく.
生成した配列番号を記憶しておくためにはグローバル変数に入れると良い.
100 array $a ! // $a に生成した配列の番号を設定
300 $a @ 5 a! // $a に入っている配列番号の配列の 5 番目の要素と
// して 300 を入れる
$a @ 5 a@ // $a に入っている配列番号の5番目の要素をスタック
// トップに置く
$a @ free // $a に入っている配列番号の配列を解放する
while は後ろに2つの文をとる.最初の文は条件として扱われ,これを 実行した結果が真なら第2の文が実行され,再度 while の文が実行される. ここで,条件判定結果はスタックからポップされることに注意.
10 f 5 2 g +
と書くより
{10 f} {5 2 g} +
と書いた方が分かりやすいだろう.
あとで言語の処理系の性能評価などが出てくるので,使った PC の 性能などを書いておく.だいぶ古い PC であるが多くの端子がついているなど 高機能な PC である.例えば,RS232C とか :-).
次の3つのプログラムを書いてみた感想を述べる.
これらを選んだ理由は基本的に(再帰)関数呼び出し,条件分岐,ループがあれば 計算理論的には任意の関数が作れること.ただし,計算理論で扱うZは無限長の理想的な整数で, これを使って配列を作ることができるので,別途,配列を使ったプログラムを作ってみる. また,関数呼び出しの時,引数が複雑になったときに人間がどれくらいの負荷を感じるか知りたい, という理由である.
これらのソースプログラムは次のようになる.
deffib { if {0th 2 <} {pop 1} { {0th 1 - fib} {swap 2 - fib} + } } ; defhanoi // n c b a if {0th 1 <} { pop pop pop pop } { 0 th $n ! 1 th $c ! 2 th $b ! 3 th $a ! $a @ $c @ $b @ $n @ 1 - hanoi 0 th $n ! 1 th $c ! 2 th $b ! 3 th $a ! "move " .% $a @ .% " to " .% $b @ .% cr $c @ $b @ $a @ $n @ 1 - hanoi pop pop pop pop } ; defprime $n ! // upperbound $n @ isqrt $m ! // $m := isqrt($n) $n @ array $primes ! // set an array of size $n to $primes "1. Set all elements to 1\n" .% 1 $i ! while { $i @ $n @ < } { 1 $primes @ $i @ a! // $primes[$i] = 1 $i @ 1 + $i ! } "2. Sieve\n" .% 2 $i ! while { $i @ $m @ <= } { if {$primes @ $i @ a@} { {$i @ $i @ +} $j ! while {$j @ $n @ <} { 0 {$primes @} {$j @} a! {{$j @} {$i @} +} $j ! } } endif {$i @ 1 +} $i ! } "3. Output\n" .% 2 $i ! 0 $count ! while {$i @ $n @ <} { if {$primes @ $i @ a@} { $i @ . " " .% $count @ 1 + $count ! } endif $i @ 1 + $i ! } "\nCount = " .% $count @ . cr "End\n" .% ; defstart-fib 10 fib . cr ; defstart-hanoi "a" "b" "c" 4 hanoi ; defstart-prime 1000 prime ; defstart start-fib ;
各プログラムを書くとき感じた感想は以下の通りである.
deffib { if {0th 2 <} {pop 1} { {0th 1 - fib} {swap 2 - fib} + } } ; def start 10 fib . cr ;
ここでの if 文は,else-part を省略できず,
if { ... } { ... } { ... }
のようになるので,
if {...} {...}
次の文
のようにやってしまい,次の文が if の else-part として取られることがあった.
これは,
def endif ;
と定義しておいて,if を
if {...} {...} {...} endif
if {...} {...} endif
という使い方を推奨することで防げると思う.余計な endif の分だけオーバーヘッドは
あるので,まったく効果を持たないキーワードを定義できるようにしても良いかもしれない.
deffib { if {0th 2 <} {pop 1} {0th 1 - fib swap 2 - fib + } } ;
と書くこと,あるいは,もっと複雑な文の列を区切らずに書くことと 比べてみればわかると思う.同様の効果は,「,」をまったく効果を持たない キーワードとして,視認性を挙げる目的で導入しても得られる.
deffib { if {0th 2 <} {pop 1} {0th 1 - fib, swap 2 - fib, + } } ;
条件文1 while {...実行文... 条件文1}
こんな感じである.同じ条件文1 を二回書くのは,間違えの元であるので,結局
while 条件文 {... 実行文...}
の形にした.if 文の構文を決めるときは,この while 文との整合性を保つために if の 後ろに書くようにしたわけである.これは同時に条件文を {, } で囲むことを強要することになり, 視認性には貢献したように思う.
・Forth の if-文と ループの書き方
defhanoi // n c b a if {0th 1 <} { pop pop pop pop } { 0 th $n ! 1 th $c ! 2 th $b ! 3 th $a ! $a @ $c @ $b @ $n @ 1 - hanoi 0 th $n ! 1 th $c ! 2 th $b ! 3 th $a ! "move " .% $a @ .% " to " .% $b @ .% cr $c @ $b @ $a @ $n @ 1 - hanoi pop pop pop pop } ; def start "a" "b" "c" 4 hanoi ;
このプログラムは結構難しかった.上のプログラムはグローバル変数 $n, $a, $b, $c を使っているが,これは別に使わなくとも,スタックに 蓄積されているデータを使えばできる.しかし,計算や再帰呼び出しの ために,取り出した値を再度スタックに積むので,いま,スタックがどうなっているか 想像するのがかなり難しい.もちろん,1つスタックに積んだら,取り出す位置が 1つ増えることを忠実に計算すればわかるのだろうが,これが中々難しい. 我々の言語ではスタックトップから n 番目 の要素をスタックに積むには, 例えば, n = 3 の時は,
3 th
と掛ける.さらにそれより一つ下のデータをその上に積むには,
5 th
となる.それでは,つぎに最初 2 番目にあったものを上に積むには ? th に なるだろうか? 実は私はすでに分からなくなっている.こんなことを続けて, スタックに積んでいくのは至難の業だと思う.とても正しいプログラムが 作れるような気がしない.
という訳で,ここではグローバル変数を使っている.いったん,$n, $a, $b, $c に 入れてしまえば,あとはこれらを参照して正しくスタックに積めるのではあるが, こちらはこちらで,このグローバル変数は再帰呼び出しの間に変えられてしまう可能性が あるので,再帰呼び出しの後に再度設定しなければならない.これも誤りを誘発する 要因になり得る.
また,hanoi の関数は,スタックに問題となるデータが積まれ,その問題を解いた後, スタックからその問題をポップしなければならない.それが上のプログラムで
pop pop pop pop
となっているところであるが,これをどこに置かないといけないのかは良く考えないと ポップしなかったり,余計にポップしてたりと,バグの発生の要因となり得る.
以上をまとめると,プログラマのスタック操作だけで,引数を渡したり, ローカル変数を実現させるのはとても分かりにくく,危険である. 近代の言語がパラメータ渡しやローカル変数を発明してくれて,とても 楽になったと実感した.
もう一つ,ここではグローバル変数の機構
を導入しているが,やはり,この書き方は結構間違いやすい.ここは文法的には 実際の Forth と殆ど同じである.Forth ではまず,変数の宣言がいるが,我々は $ で始まる名前は宣言されているものとして使って良い.Forth でも我々の言語でも 変数がプログラムに現れたら,その変数を表すもの,我々の言語では変数の番号が スタックに積まれ,Forth では変数のアドレスがスタックに積まれる.後は,@ で スタックトップの変数の値を参照,! で,スタックの2番目のデータをスタック トップの変数に設定する.どちらにしても,変な変数番号,変なアドレスが スタックに積んであれば,システムを壊してしまう操作が行われる.非常に危険 である.これは C 言語のポインタでも同じような危険性があるが,この言語と Forth の場合は,それが起こりやすい.ここでの教訓は次のようなものだろうか.
defprime $n ! // upperbound $n @ isqrt $m ! // $m := isqrt($n) $n @ array $primes ! // set an array of size $n to $primes "1. Set all elements to 1\n" .% 1 $i ! while { $i @ $n @ < } { 1 $primes @ $i @ a! // $primes[$i] = 1 $i @ 1 + $i ! } "2. Sieve\n" .% 2 $i ! while { $i @ $m @ <= } { if {$primes @ $i @ a@} { {$i @ $i @ +} $j ! while {$j @ $n @ <} { 0 {$primes @} {$j @} a! {{$j @} {$i @} +} $j ! } } endif {$i @ 1 +} $i ! } "3. Output\n" .% 2 $i ! 0 $count ! while {$i @ $n @ <} { if {$primes @ $i @ a@} { $i @ . " " .% $count @ 1 + $count ! } endif $i @ 1 + $i ! } "\nCount = " .% $count @ . cr "End\n" .% ; def start 1000 prime ;
これを実行すると次のような出力がでる.
1. Set all elements to 1 2. Sieve 3. Output 2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97 101 103 107 109 113 127 131 137 139 149 151 157 163 167 173 179 181 191 193 197 199 211 223 227 229 233 239 241 251 257 263 269 271 277 281 283 293 307 311 313 317 331 337 347 349 353 359 367 373 379 383 389 397 401 409 419 421 431 433 439 443 449 457 461 463 467 479 487 491 499 503 509 521 523 541 547 557 563 569 571 577 587 593 599 601 607 613 617 619 631 641 643 647 653 659 661 673 677 683 691 701 709 719 727 733 739 743 751 757 761 769 773 787 797 809 811 821 823 827 829 839 853 857 859 863 877 881 883 887 907 911 919 929 937 941 947 953 967 971 977 983 991 997 Count = 168 End
プログラムの最初の
$n !
はスタックトップで与えられた整数を $n に入れているのだが, $n に何を入れているか分かりにくい.例えば,何もしない関数 arg を 作って,
arg $n !
とした方が分かりやすいかもしれない.
次に配列の生成だが,この言語では例えば,
100 array
で,要素が整数で大きさが 100 の配列が生成され,その配列番号が 100 をポップして,スタックトップにプッシュされる.ここで配列番号と 述べたが,この言語では配列を管理するテーブルがあり,そのテーブル 内の番号で配列を識別している.これは実際の Forth では直接アドレスを 置いているように思われる.したがって,Forth の場合は配列は,その 先頭を指すポインタとして扱われ,n 番目の要素の参照設定は,ポインタから 要素分だけアドレスを増やした場所への参照(@),設定(!)と解釈される.
cells は1つのデータのサイズ.上のコードは, 16 cells の配列を生成して それを変数 sixteen にいれ, 51 をその 3 番目に入れ, その 3 番目を参照するコードである.
sixteen はアドレスなので,それに 3 cells 分足したところに ! すれば,そのアドレスにデータを設定できる.参照も同様である.
こちらではグローバル変数の宣言は必要ないので,直接 配列を生成するところから始まっている.まず 16 個の 整数を格納できる配列を生成して,その配列番号をグルーバル 変数 $sixteen に入れている.次にその配列の 3 番目の要素に 51 を入れるところだが,少し,実際の Forth と異なる. こちら側では,
$sixteen @
としないと,その配列番号が取り出せない.また,取り出せたのは 配列番号であり,アドレスではないため,そこに直接 ! はできない. そのため,こちらでは配列の n 番目の要素にデータを入れると言う 新たな操作 a! を導入している.参照も同様に専用の参照の操作 a@ が使われている.
上で見てきたように,配列のアドレスを直接使うか,配列番号を使うかで 記述法に若干の違いがある.アドレスを使う方は何で + なんだと思うかもしれない. 配列番号を使う方は,配列を保持している変数からの値の取り出しと,!, @ 以外の 値の設定・取得捜査 a!, a@ が導入され,プログラマは頭を悩ませる.
実は,この設定と参照は,自分自身結構悩んだ.上のエラトステネスのプログラムを 作るのは,処理系をデバッグ中だったこともあり,午前中半日位使っている. 配列の分かりやすい操作を行うことはプログラミング言語設定で重要だと感じた.
他のトピックスとしては,構造体が必要かやそのほか近代的なプログラミング言語の 概念の評価があると思うが,ここでは非常に小さな仕様の言語開発を考えているので, それらの概念についての評価までは進まず,これで終わる.
どのような実装をすれば,どのくらいの効率が達成されて,それは他の 言語の利用とどちらが効率が良いかを把握しておくのは重要なことだと思う.ここでは 今回,この言語を実装した方法とプログラム実行の速度の関係を整理しておく.C 言語の プログラムを使う時は,gcc -O のオプションでコンパイルしている.使った PC の性能などは 実験環境を参照のこと.
| No. | プログラム | 処理時間(秒) |
|---|---|---|
| 1 | 本言語のインタープリタ | 2.656 |
| 2 | 本言語のインタープリタ (VM のループでフラグの参照を1つ除去) | 2.364 |
| 3 | ruby の再帰プログラム | 1.541 |
| 4 | C 言語で書いた最小限度の VM 上で ハンドコンパイルした fib を実行 (ソースプログラムを後掲) | 1.604 |
| 5 | 同上(pc, csp, dsp を局所変数化) | 1.224 |
| 6 | C 言語での再帰プログラム | 0.062 |
上の No.2 の説明は言葉たらずかもしれない.No.1 は今回作ったインタープリタだが, この仮想コードの解釈実行の差異に,一つのグローバル変数を参照していて,それが 立っていたら,1命令ごとにユーザに継続を聞くようになっている.つまり, 1命令実行するごとに,そのフラグへのアクセスが発生する訳だ.これのフラグを 見ないようにしたものが,No.2 である.この変数の参照を取るだけで,10% ほど 速くなっているので,命令実行の方にはそれほどオーバーヘッドは無いのではないかと 思われる.
No. 4 あるいは No. 5 は,機械語に変換しないで,仮想マシンのコードに変換する 限り,出し得る最高のスピードであるはずと思う(補足1).これでも,C で書いた fib より, 20 ~ 30 倍遅い.また, No.4 は ruby のコードより遅い.実を言うと, ruby の コードがこれだけ速いのは私にとって意外だった.
補足1
この後,命令セットを拡張するなどしていろいろいじっていたら,0.6秒程度まで 高速化できた.例えば,命令列 pop, push value の代わりに,スタックトップを value に置き換える 命令として set value を追加するなど.かなり場当たり的にやったので,こちらは公開しない.
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define CMAX 10000
#define DMAX 10000
enum {c_push, c_pop, c_dup, c_swap, c_add, c_sub, c_less,
c_jmp, c_jmpz, c_call, c_ret};
struct _INSTRUCTION {
int code;
void *arg;
}
code[] = { // hand-compiled fib
{c_dup}, // 0
{c_push, (void *) 2},
{c_less},
{c_jmpz, (void *) (code + 7)},
{c_pop},
{c_push, (void *) 1},
{c_jmp, (void *) (code + 16)},
{c_dup}, // 7
{c_push, (void *) 1},
{c_sub},
{c_call, (void *) (code + 0)},
{c_swap},
{c_push, (void *) 2},
{c_sub},
{c_call, (void *) (code + 0)},
{c_add},
{c_ret}, // 16
};
struct _INSTRUCTION *cstack[DMAX];
int dstack[DMAX];
struct _INSTRUCTION **csp, *pc;
int *dsp;
int main() {
int n = 35, tmp, t1, t2;
t1 = clock();
csp = cstack - 1;
dsp = dstack - 1;
*(++dsp) = n;
*(++csp) = code - 2;
pc = code;
while (pc >= code) {
// printf("pc = %p, code = %d, *dsp = %d\n", pc, pc->code, *dsp);
switch (pc->code) {
case c_push: *(++dsp) = (int) pc->arg; break;
case c_pop: dsp--; break;
case c_dup: *(dsp+1) = *dsp; dsp++; break;
case c_swap: tmp = *dsp; *dsp = *(dsp-1); *(dsp-1) = tmp; break;
case c_add: *(dsp-1) += *dsp; dsp--; break;
case c_sub: *(dsp-1) -= *dsp; dsp--; break;
case c_less: *(dsp-1) = ((*(dsp-1)) < *dsp)?1:0; dsp--; break;
case c_jmp: pc = ((struct _INSTRUCTION *) (pc->arg)) - 1; break;
case c_jmpz:
if ((*(dsp--)) == 0)
pc = ((struct _INSTRUCTION *) (pc->arg)) - 1;
break;
case c_call:
*(++csp) = pc;
pc = ((struct _INSTRUCTION *) (pc->arg)) - 1;
break;
case c_ret: pc = *(csp--); break;
}
pc++;
}
t2 = clock();
printf("fib(%d) = %d, %d mili sec\n", n, dstack[0], t2 - t1);
}
No. 5 は,このコードで,変数 pc (プログラムカウンタ), csp (コントロールスタック), dsp (データスタック) をレジスタに割り付けられるように 局所変数にしたものである.
ruby で書いた fib の再帰プログラムも念のために書いておく.
def fib(n)
if n < 2 then 1
else
fib(n-1) + fib(n-2)
end
end
この言語およびその処理系を作ってみたのは,できるだけ少ない行数で,そこそこの 書きやすさと性能を持った言語ができないか検討するためである.極端に言えば, 200 行位で,何かそれなりに動く言語処理系が作れるとありがたい.そのとき, yacc などコンパイラコンパイラの類は,そのインストールから必要になるので, できるだけ使わないで済ませたい.その処理系のソースプログラムを扱うだけで メンテナンスできるのが好ましい.今回は 650 行位になってしまい,200 行は 中々無理そうな雰囲気になってしまった.言語の機能を落とせば,配列の機能を 入れて,300 行位ならもしかしたら可能かもしれないが,今思いつく中では, アセンブラとあまり変わらないものになりそうな気がする.
私は大昔, グラフィックエディタをフリーウェアとして出したことがあり,そのとき, そのエディタをカスタマイズするのにスクリプト言語を組み込めたらなと 考えていたことがある.LISP もどきなら楽かなとも思ったが,多くの人が 分かりにくいし,インタープリタだと性能も出ないしで諦めたことがある.
前置きが長くなったが,今回,色々試作して,処理系の書き方のパターンやそれが
どのくらいの行数を必要とするのかをまとめておいた方が,次回考えるとき
役に立つだろうと思って,この章を起こした.なお,ここでの関心事はあくまで,
以下,実装の規模の説明をするために,実装方式をある程度説明する.ソースプログラムの
短さを第一に考えたこともあり,かなり下手だと思うので,こういう実装をすると
このくらいの規模になるのかということの見当のための
まず,およその処理方式を説明しておく.
まず,処理系が使うデータを大まかに説明しておく.
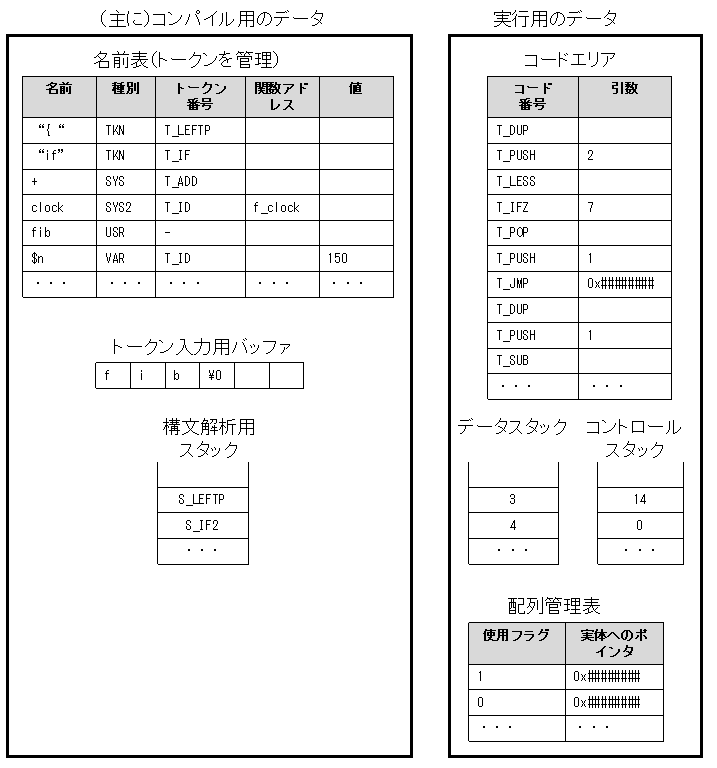
左側に囲ったものが主にコンパイル(構文解析とコード生成)用のデータである. 主にと書いたのは,名前表は,システムやユーザの関数定義,変数の定義とその値の保持 にも使っていて,実行時も使うからである.
左の枠内には次の3つがある.
少し,設計上の反省を書いておく.
通常の実装では,これは検索が効率よく出来るようにハッシュなどの方法を 使って実装するのだろうが,ここではソースプログラムを短く書くことを 第一の目的にしたことと,コンパイル時に多少遅くなる可能性はあるが,実行時には 速度的な問題はないことから線形探索を使う最も素朴なものとした.
右側はコンパイルされたコードを実行するためのデータである.これは次の4つからなる.
これらのデータの用意のもとに,プログラムの処理は次のように進む.
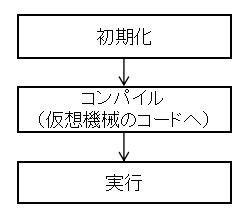
Forth はユーザが入力した命令を即座に実行するモードがあるが,今回はそのモードは 作らなかった.それを作る場合は少し,read-eval-print loop (REPL) を作るために コーディングが必要になってくる.
上記のデータ構造と処理の流れを踏まえて,処理系の主なパートとその行数を 纏めておく.読みやすさのために適当に開けた空行をどこに含めるかなど, 数えるときの揺れがあるかもしれないので,あくまで大雑把な値としてみて欲しい.
| No. | パート | 内容 | 行数 | 行数 |
|---|---|---|---|---|
| 先頭のコメント | - | 6 | 6 | |
| インクルード | - | 7 | 7 | |
| 関数プロトタイプ | - | 6 | 6 | |
| 名前表管理 | 定数定義 | 1 | 94 | |
| トークン種別定義 (enum) | 2 | |||
| トークン番号定義 (enum) | 11 | |||
| 名前表の型定義 | 8 | |||
| 名前表の初期データ定義 | 45 | |||
| 名前表アクセス関数とマクロ search(), intern(), clone_string() | 27 | |||
| コードエリア管理 | 定数 | 1 | 48 | |
| 型および変数定義 | 8 | |||
| コードの記号表示(逆アセンブル) | 39 | |||
| 解釈実行 | 定数定義 | 2 | 171 | |
| スタックなどのデータ宣言 | 6 | |||
| 本体(巨大 switch 文(30 case)) | 163 | |||
| 実行時関数 | 配列:定数定義 | 1 | 71 | |
| 配列:管理用の型と変数宣言 | 8 | |||
| 配列:生成関数 | 23 | |||
| システム2関数の実行時登録関数 | 8 | |||
| 諸実行時関数 f_push_clock,f_isqrt, f_readint, f_th | 31 | |||
| コンパイル (構文解析+コード生成) | 定数定義 | 2 | 209 | |
| 型と変数宣言 | 2 | |||
| コンパイルファイル処理 | 13 | |||
| 構文解析+コード生成 | 124 | |||
| トークンリーダ | 68 | |||
| エラー処理 | - | 5 | 5 | |
| main | 初期化 | 5 | 5 | |
| main (内 argv[] の処理が 20 行) | 32 | 32 | ||
| 合計 | - | - | 655 |
で,この表はどうつかうかというと,
全体で C 言語 200 行に抑えるためには,どこをどのくらいに抑える必要があるかな? 配列は作れるかな?などと思いを巡らせるために使うのである.ちなみに C 言語 200 行でできる可能性が あるかというと,if, while 無しの超簡易アセンブラレベル,変数無し,配列無しの 言語だと,320 行で書いた実績はある.このレベルで昔の TECO (Text Editor and Corrector) の ように1文字コマンドにして,なんとか,チューリング完全で 200 行前後にならんだろうか? もう,殆ど趣味の領域だけど.
以下,「実行系」と「構文解析+コード生成」について個別に議論する.
仮想機械の実行系は典型的には,次のように switch 文のお化けにするか, あるいは,その次に書いたように,命令のコードや引数から呼び出す関数を決定して それを呼び出すか,あるいは,その融合かになると思う.第3の融合方式はとりあえず置いておき,前者を前2つの方式で処理系のサイズがどうなるかを考えてみよう,ここでは 仮に,前者を(1)巨大 switch 文方式,後者を(2)関数ポインタ方式と呼ぶことにする.
int exec(start) {
初期化処理;
pc = start;
while (pc が有効な値) {
switch (pc->code) {
case I_PUSH:
push(pc->arg);
break;
case I_POP:
pop();
break;
...
}
pc++;
}
}
この書き方だと,
2×機能数加えた行数になる.
int exec(start) {
初期化処理;
pc = start;
while (pc が有効な値) {
(*instruction[pc->code])(pc);
pc++
}
}
4×機能数加えた行数が必要になる.
また,例えば,ジャンプ命令を実現しようと思うと,呼ばれた関数から どうやって,仮想機械のプログラムカウンタへアクセスするかが問題になる. プログラムカウンタを大域変数にとると,レジスタに割り当てられなくなり 遅くなる恐れがある.
上記のことから,今回作成した言語では両方の呼び出しをサポートし,別のシステムに 組み込むときは,実行時にその関数を組み込めるようにした.このとき,どれだけを 解釈実行ルーティンのswitch文で処理するのが良いのかは,言語設計・実装の ポイントとなる.
今回は,switch で 30 個の機能を実装し,171 行になった.どんなものを実装したかを 一応,載せておく.これは,今後,ここでどんな機能が必要になるかを考えるときの 材料になると思うからである.分かりにくい命令は簡単に説明を書いている.
ちょっと長くなるが,巨大な switch 文にした場合と,命令を関数ポインタにして 呼び出した場合の速度比較もしておきたい.そのためのテストプログラムを 次にあげておく.
/*
Comparison between exec of a switch and exec of function pointers
for 32bit model
*/
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define N (100*1000*1000)
#define SLEN 1000
enum {fi_push, fi_sub, fi_jmp, fi_jmpz, fi_end};
struct _INST1 {
int code;
void *arg;
} code1[] = {
{fi_push, (void *) N},
{fi_jmpz, (void *) (code1 + 4)},
{fi_sub, (void *) 1},
{fi_jmp, (void *) (code1 + 1)},
{fi_end},
};
void fun_push();
void fun_jmpz();
void fun_sub();
void fun_jmp();
void fun_end();
struct _INST2 {
void (*f)();
void *arg;
} code2[] = {
{fun_push, (void *) N},
{fun_jmpz, (void *) (code2 + 4)},
{fun_sub, (void *) 1},
{fun_jmp, (void *) (code2 + 1)},
{fun_end},
};
int stack[SLEN];
int *sp;
struct _INST1 *pc1;
struct _INST2 *pc2;
int endp;
void exec1(struct _INST1 *code) {
// register struct _INST1 *pc1; // remove the first // for optimized test
// register int endp, *sp; // same as above
pc1 = code;
sp = stack - 1;
endp = 0;
while (!endp) {
switch (pc1->code) {
case fi_push: *(++sp) = (int) (pc1->arg); break;
case fi_sub: *sp -= (int) (pc1->arg); break;
case fi_jmp: pc1 = (struct _INST1 *) (pc1->arg); continue;
case fi_jmpz:
if ((*sp) == 0) {
pc1 = (struct _INST1 *) (pc1->arg);
continue;
}
break;
case fi_end: endp = 1;
}
pc1++;
}
}
void fun_push(struct _INST2 *c) {
(*(++sp)) = (int) (c->arg);
}
void fun_sub(struct _INST2 *c) {
(*sp) -= (int) (c->arg);
}
void fun_jmpz(struct _INST2 *c) {
if ((*sp) == 0)
pc2 = ((struct _INST2 *) (c->arg)) - 1;
}
void fun_jmp(struct _INST2 *c) {
pc2 = ((struct _INST2 *) (c->arg)) - 1;
}
void fun_end(struct _INST2 *c) {
endp = 1;
}
void exec2(struct _INST2 *code) {
pc2 = code;
endp = 0;
sp = stack - 1;
while (!endp) {
(*(pc2->f))(pc2);
pc2++;
}
}
int main(void) {
int t1;
t1 = clock();
exec1(code1);
printf("time of exec1 = %d mili sec\n", clock() - t1);
t1 = clock();
exec2(code2);
printf("time of exec1 = %d mili sec\n", clock() - t1);
return 0;
}
exec1() は switch 文で命令の動作を分岐しており,exec2() は,命令の code 部分に 命令を実装する関数ポインタがあるとして,命令語を引数にその関数を呼ぶだけの プログラムである.どちらも実行するプログラムは 100,000,000 から 1 ずつ引いていって 0 になったら終わるプログラムである.命令の関数呼び出しの部分以外で差が出ないように exec1() のループではわざわざ大域変数の, pc1, sp, endp を参照するようにしている. 計測はこの条件で exec1() と exec2() を実行したものと,それから,上で 述べた変数 pc1, sp, endp を exec1() ではレジスタ割り付けできるようにしたもの の3つを比較する.最後のものは,exec1 の最初のコメント記号 // を外して, レジスタ変数 pc1, sp, endp を有効にすればよい.実行環境は今までと 同じである.
| 方式 | 時間(ミリ秒) |
|---|---|
| exec1() swtch文で分岐 | 896 |
| exec2() 関数ポインタで呼び出し | 1229 |
| exec1() で pc1, sp, endp をレジスタ割り付けしたもの | 562 |
この表を見ると関数ポインタの実装でもそこまで遅くないように思うが, この測定では関数ポインタを呼ぶ分だけを測っている訳ではないから, 解釈実行のループ部分のオーバーヘッドが少なくなれば,もう少し差は開くはずである. 3つ目の測定値を見ると, その他の部分,つまり,プログラムカウンタ pc1 ,データスタック sp ,終わりの判定の endp をレジスタ割り付けできるとずいぶんと速くなっている.
今回は,パーサは yacc などのツールを使わずに手でゴリゴリ書いた. やはり,色々なところでコンパイルして使うのに,いちいちパーサジェネレータを まずインストールしてというのは,自分がやるのも人にやらせるのも好きでない. それでパーサの書きやすさと言語仕様の人間への優しさとが,ある折衷案に落ち着くことに なる.ここで言えば,
if {...} {...} {...} v.s. if {...} then {...} else {...}
などだろうか? この例はどちらも人間に優しくないかもしれないが.
どちらにしても,この程度のパーサとコード生成で, 表.言語処理系の行数 に示すように,124 行掛かっている. ここでは if の後に文を3つ読んで,それぞれコード生成を行わないといけないので, パーサのスタックに積む状態として,S_IF1, S_IF2, S_IF3 を用意しておき,関連情報と 一緒にパーサのスタックに積み,3つの文を読むごとに,これらの if の状態を進めていく 処理をしている.
今回開発した言語では,if 以外に, while {...} {...} もあるので,このパーサスタック上の 状態遷移はほぼ2倍になる.これは次回はある程度,状態遷移表のような表を解釈する 形にした方が良いかもしれない.また, ここではスタックを使って非再帰的なプログラムにしたが,もしかしたら,再帰プログラムの 方が簡単に書けるかもしれない.そのうちやってみてうまく行ったらここに書くことにする.
ここでは,スタックマシンの系統の仮想機械で実現されるプログラミング言語の 実装方法を検討した.趣味の領域であるが,ツールを使わずに,普通の C 言語で できるだけ短く書くための下になる検討や測定結果を載せた.
Forth を初めて知ったのは,1982 年位だったと思う.大学の4年までは数学専攻 だったが,5年生で初めて計算機の方に方向変えした.そのとき,一緒のゼミに 参加していた友達が確かシャープの MZ なんたらという PC だったと思うが, そういうものを持っていて,「こんな面白い言語があるよ」と教えてくれた. そのときは,「へー,面白いね」と言ったきり,実際には Forth を覚えたわけでは ないので,概念的には知ってるけど,使ったことがないので,どんな使い勝手か まったくわからない言語だった.
それを今回,gForth を使ってみたり,Forth もどきの言語を作ってみたりして 実感としてどんなものか大分分かってきた.んー,スタックがどうなっているか すぐわからなくなる.ハノイの塔の問題でさえ,私にはスタックだけでは うまくプログラミングできない.C 言語みたいに,パラメータを明示する プログラミング言語の有難さがしみじみ分かってくる.
でも,これも処理系が短くできる技なので,なにか他の技法と合わせれば,もっと 使いやすくなるかもしれない.今回は,たまたまやってみて,「どんな使い勝手なんだろう?」 という今までのもやもやした疑問が解消できてよかった.また,すごく小さな言語を 作るのは純粋に興味深い.
このページを書いてからも,もう一度,このページに書いたような言語の トランスレータおよびインタープリタを書いている.このバージョンは コンパイラというか構文解析を再帰的に書いたので少し短くなり,440 行で できた.
で,結構,これはいろいろ挑戦してみるのに面白い題材なので,挑戦するための システムの仕様を書いておく.
この仕様でもう少し短く, 300 行台には行きそうな気はするのだが(やってないけど),また, 継続してやってみようと思う.
また,言語のとても短い実装として参考文献にも挙げたが
dyama's pageというページを見つけた.直接リンクはしないが,上のタイトルでぐぐれば見つかるだろう. VTL は Basic -like な非常に簡単な言語である.7行といっても,最初の2行にインクルード文 があり,あとは,80 カラムまで詰めて良いみたいなので,80文字 × 5 行 = 400 文字に インクルード文を入れた 430 文字くらいのプログラムである.goto が無いので,その人も 言っているが,「変数が使える電卓」レベルのものだが,私にはなかなかできそうにない.
VTL (Very Tiny Language)の実装を七行プログラミングで挑戦してみました
リンク切れを気にしたくないので,直接のリンクは張らないことが多い.申し訳ないが, そこに書いてある名称などで検索していただきたい.
で検索すると,Nakagawa さんの,VTLを作ってみたというページが見つかると思う. また,Nakagawa さんは,「Tiny Forthインタープリタ」も作ったみたいなので,VTL (Very Tiny Language) の作成 T. Nakagawa
で検索すると,Forth に関しても有益な情報が得られると思う.この Tiny Forth は,584 行 + α (処理系依存の getchr() ) で実装されている.変数は実装して いるが,配列は実装していないように見える(そのページの 2010-01-30 版).私は先頭以外コメントを書かなかったが この人は,きちんと各関数ごとにコメントを書いている.Tiny Forthインタープリタ Nakagawa
というページがあって,7 行の VTL のコードが置かれている. これはかなり詰め込んで書かれていて,何がなんだかわからない.でも, その後に,この圧縮形になる前の比較的人間に読みやすい形の 69 行の処理系が書かれている. 7行じゃなくても,こちらでもすごい. これをみると,Forth-like な言語,200 行以内というのも夢では ないかもしれない.VTL (Very Tiny Language)の実装を七行プログラミングで挑戦してみました
VTL系言語の歴史というページがあった.いくつかが表になってて分かりやすいと思う. ここの人は,自分でも rvtl という名前を付けた言語を作っているらしい. 作者の名前は Jun Mizutani と書いてあるので,上のキーワードと合わせて 検索するとすぐ出てくると思う.
今(2019.04.10)調べたら,
当面リンクお断り致します。m(__)mと書いてあるので,リンクは張らない.もっとも,他のページへの リンクも張ってないが.ここは google で 検索すると geocities.jp のページがヒットする. 私のところもだけど,geocities.jp が 2019.03.31 で閉鎖なので,新しい サイトに移られたみたいだ.
ん? これはもしかしたら間接的にリンクを張っていることになるのかな? シンボリックリンクだよね.それも検索という,途中,不確定なものを 含んだ.
計算機(主にソフトウェア)の話題 へ
圏論を勉強しよう へ
束論を勉強しよう へ
半群論を勉強しよう へ
ホームページトップ(Top of My Homepage)